Algorithm principles and implementation with YOLOv8¶
0 Introduction¶
 Figure 1:YOLOv8-P5
Figure 1:YOLOv8-P5
RangeKing@github provides the graph above. Thanks, RangeKing!
YOLOv8 is the next major update from YOLOv5, open sourced by Ultralytics on 2023.1.10, and now supports image classification, object detection and instance segmentation tasks.
 Figure 2:YOLOv8-logo
Figure 2:YOLOv8-logo
However, instead of naming the open source library YOLOv8, ultralytics uses the word ultralytics directly because ultralytics positions the library as an algorithmic framework rather than a specific algorithm, with a major focus on scalability. It is expected that the library can be used not only for the YOLO model family, but also for non-YOLO models and various tasks such as classification segmentation pose estimation.
Overall, YOLOv8 is a powerful and flexible tool for object detection and image segmentation that offers the best of both worlds: the SOTA technology and the ability to use and compare all previous YOLO versions.
 Figure 3:YOLOv8-performance
Figure 3:YOLOv8-performance
YOLOv8 official open source address: this
MMYOLO open source address for YOLOv8: this
The following table shows the official results of mAP, number of parameters and FLOPs tested on the COCO Val 2017 dataset. It is evident that YOLOv8 has significantly improved precision compared to YOLOv5. However, the number of parameters and FLOPs of the N/S/M models have significantly increased. Additionally, it can be observed that the inference speed of YOLOv8 is slower in comparison to most of the YOLOv5 models.
| model | YOLOv5 | params(M) | FLOPs@640 (B) | YOLOv8 | params(M) | FLOPs@640 (B) |
|---|---|---|---|---|---|---|
| n | 28.0(300e) | 1.9 | 4.5 | 37.3 (500e) | 3.2 | 8.7 |
| s | 37.4 (300e) | 7.2 | 16.5 | 44.9 (500e) | 11.2 | 28.6 |
| m | 45.4 (300e) | 21.2 | 49.0 | 50.2 (500e) | 25.9 | 78.9 |
| l | 49.0 (300e) | 46.5 | 109.1 | 52.9 (500e) | 43.7 | 165.2 |
| x | 50.7 (300e) | 86.7 | 205.7 | 53.9 (500e) | 68.2 | 257.8 |
It is worth mentioning that the recent YOLO series have shown significant performance improvements on the COCO dataset. However, their generalizability on custom datasets has not been extensively tested, which thereby will be a focus in the future development of MMYOLO.
Before reading this article, if you are not familiar with YOLOv5, YOLOv6 and RTMDet, you can read the detailed explanation of YOLOv5 and its implementation.
1 YOLOv8 Overview¶
The core features and modifications of YOLOv8 can be summarized as follows:
A new state-of-the-art (SOTA) model is proposed, featuring an object detection model for P5 640 and P6 1280 resolutions, as well as a YOLACT-based instance segmentation model. The model also includes different size options with N/S/M/L/X scales, similar to YOLOv5, to cater to various scenarios.
The backbone network and neck module are based on the YOLOv7 ELAN design concept, replacing the C3 module of YOLOv5 with the C2f module. However, there are a lot of operations such as Split and Concat in this C2f module that are not as deployment-friendly as before.
The Head module has been updated to the current mainstream decoupled structure, separating the classification and detection heads, and switching from Anchor-Based to Anchor-Free.
The loss calculation adopts the TaskAlignedAssigner in TOOD and introduces the Distribution Focal Loss to the regression loss.
In the data augmentation part, Mosaic is closed in the last 10 training epoch, which is the same as YOLOX training part. As can be seen from the above summaries, YOLOv8 mainly refers to the design of recently proposed algorithms such as YOLOX, YOLOv6, YOLOv7 and PPYOLOE.
Next, we will introduce various improvements in the YOLOv8 model in detail by 5 parts: model structure design, loss calculation, training strategy, model inference process and data augmentation.
2 Model structure design¶
The Figure 1 is the model structure diagram based on the official code of YOLOv8. If you like this style of model structure diagram, welcome to check out the model structure diagram in algorithm README of MMYOLO, which currently covers YOLOv5, YOLOv6, YOLOX, RTMDet and YOLOv8.
Comparing the YOLOv5 and YOLOv8 yaml configuration files without considering the head module, you can see that the changes are minor.
 Figure 4:YOLOv5 and YOLOv8 YAML diff
Figure 4:YOLOv5 and YOLOv8 YAML diff
The structure on the left is YOLOv5-s and the other side is YOLOv8-s. The specific changes in the backbone network and neck module are:
The kernel of the first convolutional layer has been changed from 6x6 to 3x3
All C3 modules are replaced by C2f, and the structure is as follows, with more skip connections and additional split operations.
 Figure 5:YOLOv5 and YOLOv8 module diff
Figure 5:YOLOv5 and YOLOv8 module diff
Removed 2 convolutional connection layers from neck module
The block number has been changed from 3-6-9-3 to 3-6-6-3.
If we look at the N/S/M/L/X models, we can see that of the N/S and L/X models only changed the scaling factors, but the number of channels in the S/ML backbone network is not the same and does not follow the same scaling factor principle. The main reason for this design is that the channel settings under the same set of scaling factors are not the most optimal, and the YOLOv7 network design does not follow one set of scaling factors for all models either.
The most significant changes in the model lay in the head module. The head module has been changed from the original coupling structure to the decoupling one, and its style has been changed from YOLOv5’s Anchor-Based to Anchor-Free. The structure is shown below.
 Figure 6:YOLOv8 Head
Figure 6:YOLOv8 Head
As demonstrated, the removal of the objectness branch and the retention of only the decoupled classification and regression branches stand as the major differences. Additionally, the regression branch now employs integral form representation as proposed in the Distribution Focal Loss.
3 Loss calculation¶
The loss calculation process consists of 2 parts: the sample assignment strategy and loss calculation.
The majority of contemporary detectors employ dynamic sample assignment strategies, such as YOLOX’s simOTA, TOOD’s TaskAlignedAssigner, and RTMDet’s DynamicSoftLabelAssigner. Given the superiority of dynamic assignment strategies, the YOLOv8 algorithm directly incorporates the one employed in TOOD’s TaskAlignedAssigner.
The matching strategy of TaskAlignedAssigner can be summarized as follows: positive samples are selected based on the weighted scores of classification and regression.
s is the prediction score corresponding to the ground truth category, u is the IoU of the prediction bounding box and the gt bounding box.
For each ground truth, the task-aligned assigner calculates the
alignment metricfor each anchor by taking the weighted product of two values: the predicted classification score of the corresponding class, and the Intersection over Union (IoU) between the predicted bounding box and the Ground Truth bounding box.For each Ground Truth, the larger top-k samples are selected as positive based on the
alignment_metricsvalues directly.
The loss calculation consists of 2 parts: the classification and regression, without the objectness loss in the previous model.
The classification branch still uses BCE Loss.
The regression branch employs both Distribution Focal Loss and CIoU Loss.
The 3 Losses are weighted by a specific weight ratio.
4 Data augmentation¶
YOLOv8’s data augmentation is similar to YOLOv5, whereas it stops the Mosaic augmentation in the final 10 epochs as proposed in YOLOX. The data process pipelines are illustrated in the diagram below.
 Figure 7:pipeline
Figure 7:pipeline
The intensity of data augmentation required for different scale models varies, therefore the hyperparameters for the scaled models are adjusted depending on the situation. For larger models, techniques such as MixUp and CopyPaste are typically employed. The result of data augmentation can be seen in the example below:
 Figure 8:results
Figure 8:results
The above visualization result can be obtained by running the browse_dataset script.
As the data augmentation process utilized in YOLOv8 is similar to YOLOv5, we will not delve into the specifics within this article. For a more in-depth understanding of each data transformation, we recommend reviewing the YOLOv5 algorithm analysis document in MMYOLO.
5 Training strategy¶
The distinctions between the training strategy of YOLOv8 and YOLOv5 are minimal. The most notable variation is that the overall number of training epochs for YOLOv8 has been raised from 300 to 500, resulting in a significant expansion in the duration of training. As an illustration, the training strategy for YOLOv8-S can be succinctly outlined as follows:
| config | YOLOv8-s P5 hyp |
|---|---|
| optimizer | SGD |
| base learning rate | 0.01 |
| Base weight decay | 0.0005 |
| optimizer momentum | 0.937 |
| batch size | 128 |
| learning rate schedule | linear |
| training epochs | 500 |
| warmup iterations | max(1000,3 * iters_per_epochs) |
| input size | 640x640 |
| EMA decay | 0.9999 |
6 Inference process¶
The inference process of YOLOv8 is almost the same as YOLOv5. The only difference is that the integral representation bbox in Distribution Focal Loss needs to be decoded into a regular 4-dimensional bbox, and the subsequent calculation process is the same as YOLOv5.
Taking COCO 80 class as an example, assuming that the input image size is 640x640, the inference process implemented in MMYOLO is shown as follows.
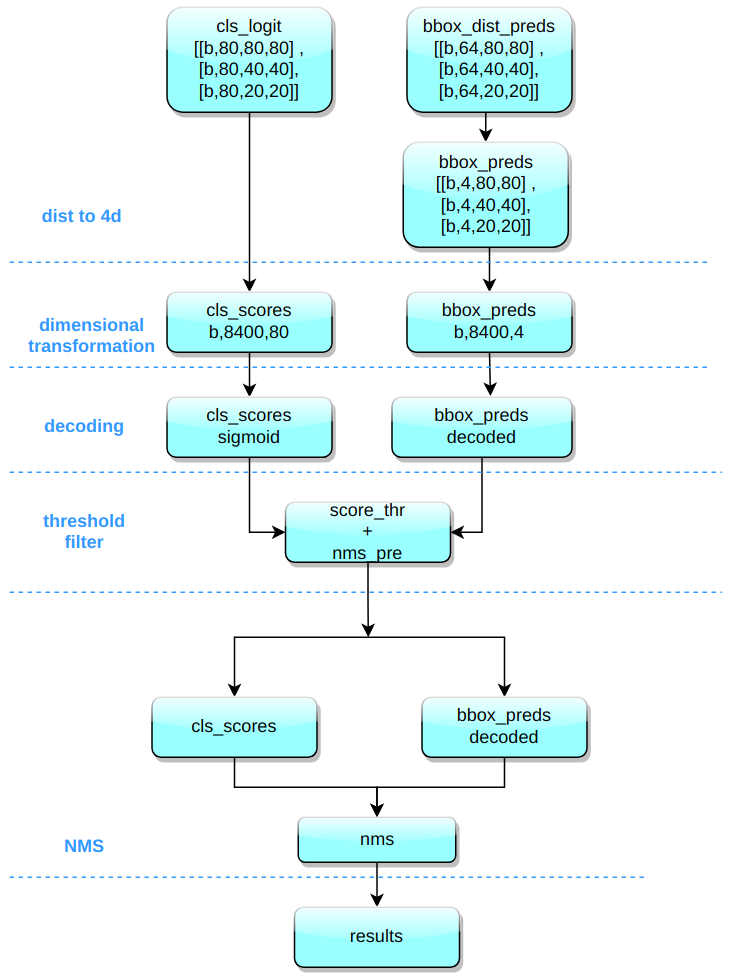 Figure 9:results
Figure 9:results
(1) Decoding bounding box Integrate the probability of the distance between the center and the boundary of the box into the mathematical expectation of the distances.
(2) Dimensional transformation
YOLOv8 outputs three feature maps with 80x80, 40x40 and 20x20 scales. A total of 6 classification and regression different scales of feature map are output by the head module.
The 3 different scales of category prediction branch and bbox prediction branch are combined and dimensionally transformed. For the convenience of subsequent processing, the original channel dimensions are transposed to the end, and the category prediction branch and bbox prediction branch shapes are (b, 80x80+40x40+20x20, 80)=(b,8400,80), (b,8400,4), respectively.
(3) Scale Restroation The classification prediction branch utilizes sigmoid calculations, whereas the bbox prediction branch requires decoding to xyxy format and conversion to the original scale of the input images.
(4) Thresholding
Iterate through each graph in the batch and use score_thr to perform thresholding. In this process, we also need to consider multi_label and nms_pre to ensure that the number of detected bboxs after filtering is no more than nms_pre.
(5) Reduction to the original image scale and NMS
Reusing the parameters for preprocessing, the remaining bboxs are first resized to the original image scale and then NMS is performed. The final number of bboxes cannot be more than max_per_img.
Special Note: The Batch shape inference strategy, which is present in YOLOv5, is currently not activated in YOLOv8. By performing a quick test in MMYOLO, it can be observed that activating the Batch shape strategy can result in an approximate AP increase of around 0.1% to 0.2%.
7 Feature map visualization¶
A comprehensive set of feature map visualization tools are provided in MMYOLO to help users visualize the feature maps.
Take the YOLOv8-s model as an example. The first step is to download the official weights, and then convert them to MMYOLO by using the yolov8_to_mmyolo script. Note that the script must be placed under the official repository in order to run correctly.
Assuming that you want to visualize the effect of the 3 feature maps output by backbone and the weights are named ‘mmyolov8s.pth’. Run the following command:
cd mmyolo
python demo/featmap_vis_demo.py demo/demo.jpg configs/yolov8/yolov8_s_syncbn_fast_8xb16-500e_coco.py mmyolov8s.pth --channel-reductio squeeze_mean
In particular, to ensure that the feature map and image are shown aligned, the original test_pipeline configuration needs to be replaced with the following:
test_pipeline = [
dict(
type='LoadImageFromFile',
backend_args=_base_.backend_args),
dict(type='mmdet.Resize', scale=img_scale, keep_ratio=False), # change
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor'))
]
 Figure 10:featmap
Figure 10:featmap
cd mmyolo
python demo/featmap_vis_demo.py demo/demo.jpg configs/yolov8/yolov8_s_syncbn_fast_8xb16-500e_coco.py mmyolov8s.pth --channel-reductio squeeze_mean --target-layers neck
 Figure 11:featmap
Figure 11:featmap
From the above figure, we can find the features at the object are more focused.
Summary¶
This article delves into the intricacies of the YOLOv8 algorithm, offering a comprehensive examination of its overall design, model structure, loss function, training data enhancement techniques, and inference process. To aid in comprehension, a plethora of diagrams are provided.
In summary, YOLOv8 is a highly efficient algorithm that incorporates image classification, Anchor-Free object detection, and instance segmentation. Its detection component incorporates numerous state-of-the-art YOLO algorithms to achieve new levels of performance.
MMYOLO open source address for YOLOV8 this
MMYOLO Algorithm Analysis Tutorial address is yolov5_description