Algorithm principles and implementation with RTMDet¶
0 Introduction¶
High performance, low latency one-stage object detection

RangeKing@github provides the graph above. Thanks, RangeKing!
Recently,the open-source community has spring up a large number of high-precision object detection projects, one of the most prominent projects is YOLO series. OpenMMLab has also launched MMYOLO in collaboration with the community. After investigating many improved models in current YOLO series, MMDetection core developers empirically summarized these designs and training methods, and optimized them to launch a single-stage object detector with high accuracy and low latency RTMDet, Real-time Models for Object Detection (Release to Manufacture)
RTMDet consists of a series of tiny/s/m/l/x models of different sizes, which provide different choices for different application scenarios. Specifically, RTMDet-x achieves a 300+ FPS inference speed with an accuracy of 52.6 mAP.
Note
Note: Inference speed and accuracy test (excluding NMS) were performed on TensorRT 8.4.3, cuDNN 8.2.0, FP16, batch size=1 on 1 NVIDIA 3090 GPU.
The lightest model, RTMDet-tiny, can achieve 40.9 mAP with only 4M parameters and inference speed < 1 ms.
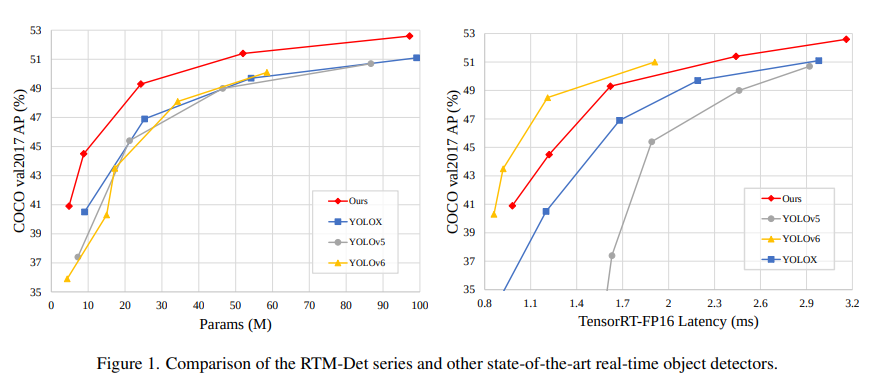
The accuracy in this figure is a fair comparison to 300 training epochs, without distillation.
| mAP | Params | Flops | Inference speed | |
|---|---|---|---|---|
| Baseline(YOLOX) | 40.2 | 9M | 13.4G | 1.2ms |
| + AdamW + Flat Cosine | 40.6 (+0.4) | 9M | 13.4G | 1.2ms |
| + CSPNeXt backbone & PAFPN | 41.8 (+1.2) | 10.07M (+1.07) | 14.8G (+1.4) | 1.22ms (+0.02) |
| + SepBNHead | 41.8 (+0) | 8.89M (-1.18) | 14.8G | 1.22ms |
| + Label Assign & Loss | 42.9 (+1.1) | 8.89M | 14.8G | 1.22ms |
| + Cached Mosaic & MixUp | 44.2 (+1.3) | 8.89M | 14.8G | 1.22ms |
| + RSB-pretrained backbone | 44.5 (+0.3) | 8.89M | 14.8G | 1.22ms |
Official repository: https://github.com/open-mmlab/mmdetection/blob/3.x/configs/rtmdet/README.md
MMYOLO repository: https://github.com/open-mmlab/mmyolo/blob/main/configs/rtmdet/README.md
1 v1.0 algorithm principle and MMYOLO implementation analysis¶
1.1 Data augmentation¶
Many data augmentation methods are used in RTMDet, mainly include single image data augmentation:
RandomResize
RandomCrop
HSVRandomAug
RandomFlip
and mixed image data augmentation:
Mosaic
MixUp
The following picture demonstrates the data augmentation process:

The RandomResize hyperparameters are different on the large models M,L,X and the small models S, Tiny. Due to the number of parameters,the large models can use the large jitter scale strategy with parameters of (0.1,2.0). The small model adopts the stand scale jitter strategy with parameters of (0.5, 2.0).
The single image data augmentation has been packaged in MMDetection so users can directly use all methods through simple configurations. As a very ordinary and common processing method, this part will not be further introduced now. The implementation of mixed image data augmentation is described in the following.
Unlike YOLOv5, which considers the use of MixUp on S and Nano models is excessive. Small models don’t need such strong data augmentation. However, RTMDet also uses MixUp on S and Tiny, because RTMDet will switch to normal aug at last 20 epochs, and this operation was proved to be effective by training. Moreover, RTMDet introduces a Cache scheme for mixed image data augmentation, which effectively reduces the image processing time and introduces adjustable hyperparameters.
max_cached_images, which is similar to repeated augmentation when using a smaller cache. The details are as follows:
| Use cache | ms / 100 imgs | |
|---|---|---|
| Mosaic | 87.1 | |
| Mosaic | √ | 24.0 |
| MixUp | 19.3 | |
| MixUp | √ | 12.4 |
| RTMDet-s | RTMDet-l | |
|---|---|---|
| Mosaic + MixUp + 20e finetune | 43.9 | 51.3 |
1.1.1 Introducing Cache for mixins data augmentation¶
Mosaic&MixUp needs to blend multiple images, which takes k times longer than common data augmentation (k is the number of images mixed in). For example, in YOLOv5, every time Mosaic is done, the information of four images needs to be reloaded from the hard disk. RTMDet only needs to reload the current image, and the rest images participating in the mixed augmentation are obtained from the cache queue, which greatly improves the efficiency by sacrificing a certain memory space. Moreover, we can modify the cache size and pop mode to adjust the strength of augmentation.
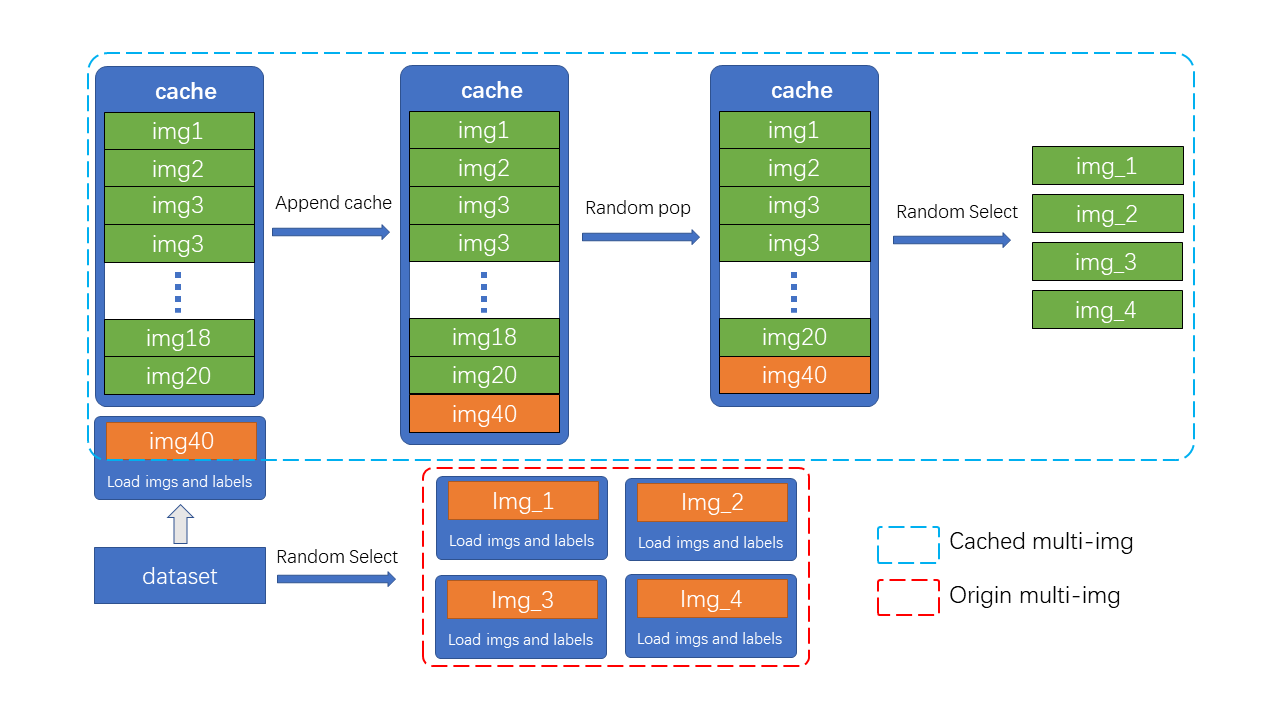
As shown in the figure, N loaded images and labels are stored in the cache queue in advance. In each training step, only a new image and its label need to be loaded and updated to the cache queue (the images in the cache queue can be repeated, as shown in the figure for img3 twice). Meanwhile, if the cache queue length exceeds the preset length, it will pop a random image (in order to make the Tiny model more stable, the Tiny model doesn’t use the random pop, but removes the first added image). When mixed data augmentation is needed, only the required images need to be randomly selected from the cache for splicing and other processing, instead of loading them all from the hard disk, which saves the time of image loading.
Note
The maximum length N of the cache queue is an adjustable parameter. According to the empirical principle, when ten caches are provided for each image to be blended, it can be considered to provide enough randomness, while the Mosaic enhancement is four image blends, so the number of caches defaults to N=40. Similarly, MixUp has a default cache size of 20, but tiny model requires more stable training conditions, so it has half cache size of other specs (10 for MixUp and 20 for Mosaic).
In the implementation, MMYOLO designed the BaseMiximageTransform class to support mixed data augmentation of multiple images:
if self.use_cached:
# Be careful: deep copying can be very time-consuming
# if results includes dataset.
dataset = results.pop('dataset', None)
self.results_cache.append(copy.deepcopy(results)) # Cache the currently loaded data
if len(self.results_cache) > self.max_cached_images:
if self.random_pop: # Except for the tiny model, self.random_pop=True
index = random.randint(0, len(self.results_cache) - 1)
else:
index = 0
self.results_cache.pop(index)
if len(self.results_cache) <= 4:
return results
else:
assert 'dataset' in results
# Be careful: deep copying can be very time-consuming
# if results includes dataset.
dataset = results.pop('dataset', None)
1.1.2 Mosaic¶
Mosaic concatenates four images into a large image, which is equivalent to increasing the batch size, as follows:
Randomly resample three images from customize datasets based on the index, possibly repeated.
def get_indexes(self, dataset: Union[BaseDataset, list]) -> list:
"""Call function to collect indexes.
Args:
dataset (:obj:`Dataset` or list): The dataset or cached list.
Returns:
list: indexes.
"""
indexes = [random.randint(0, len(dataset)) for _ in range(3)]
return indexes
Randomly select the midpoint of the intersection of four images.
# mosaic center x, y
center_x = int(
random.uniform(*self.center_ratio_range) * self.img_scale[1])
center_y = int(
random.uniform(*self.center_ratio_range) * self.img_scale[0])
center_position = (center_x, center_y)
Read and concatenate images based on the sampled index. Using the
keep-ratioresize image (i.e. the maximum edge must be 640) before concatenating.
# keep_ratio resize
scale_ratio_i = min(self.img_scale[0] / h_i,
self.img_scale[1] / w_i)
img_i = mmcv.imresize(
img_i, (int(w_i * scale_ratio_i), int(h_i * scale_ratio_i)))
After concatenating images, the bboxes and labels are all concatenated together, and then the bboxes are cropped but not filtered (some invalid bboxes may appear).
mosaic_bboxes.clip_([2 * self.img_scale[0], 2 * self.img_scale[1]])
Please reference the Mosaic theory of YOLOv5 for more details.
1.1.3 MixUp¶
The MixUp implementation of RTMDet is the same as YOLOX, with the addition of cache function similar to above mentioned.
Please reference the MixUp theory of YOLOv5 for more details.
1.1.4 Strong and weak two-stage training¶
Mosaic + MixUp has high distortion. Continuously using strong data augmentation isn’t beneficial. YOLOX use strong and weak two-stage training mode firstly. However, the introduction of rotation and shear result in box annotation errors, which needs to introduce L1 loss to correct the performance of regression branch.
In order to make the data augmentation method more general, RTMDet uses Mosaic + MixUp without rotation during the first 280 epochs, and increases the intensity and positive samples by mixing eight images. During the last 20 epochs, a relatively small learning rate is used to fine-tune under weak agumentation, and slowly update parameters to model by EMA, which could obtain a large improvement.
| RTMDet-s | RTMDet-l | |
|---|---|---|
| LSJ + rand crop | 42.3 | 46.7 |
| Mosaic+MixUp | 41.9 | 49.8 |
| Mosaic + MixUp + 20e finetune | 43.9 | 51.3 |