YOLOv5 原理和实现全解析¶
0 简介¶
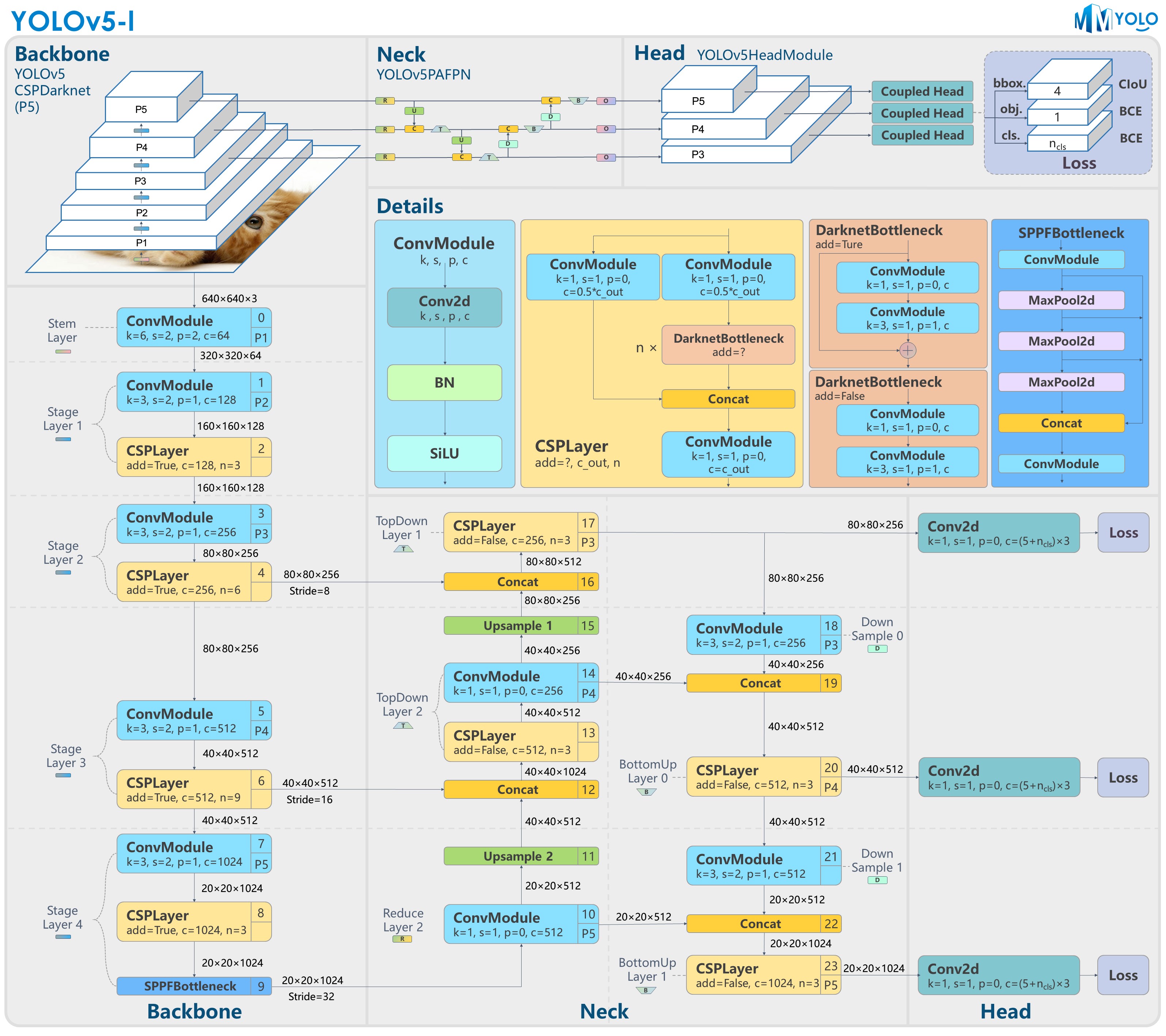 图 1:YOLOv5-l-P5 模型结构
图 1:YOLOv5-l-P5 模型结构
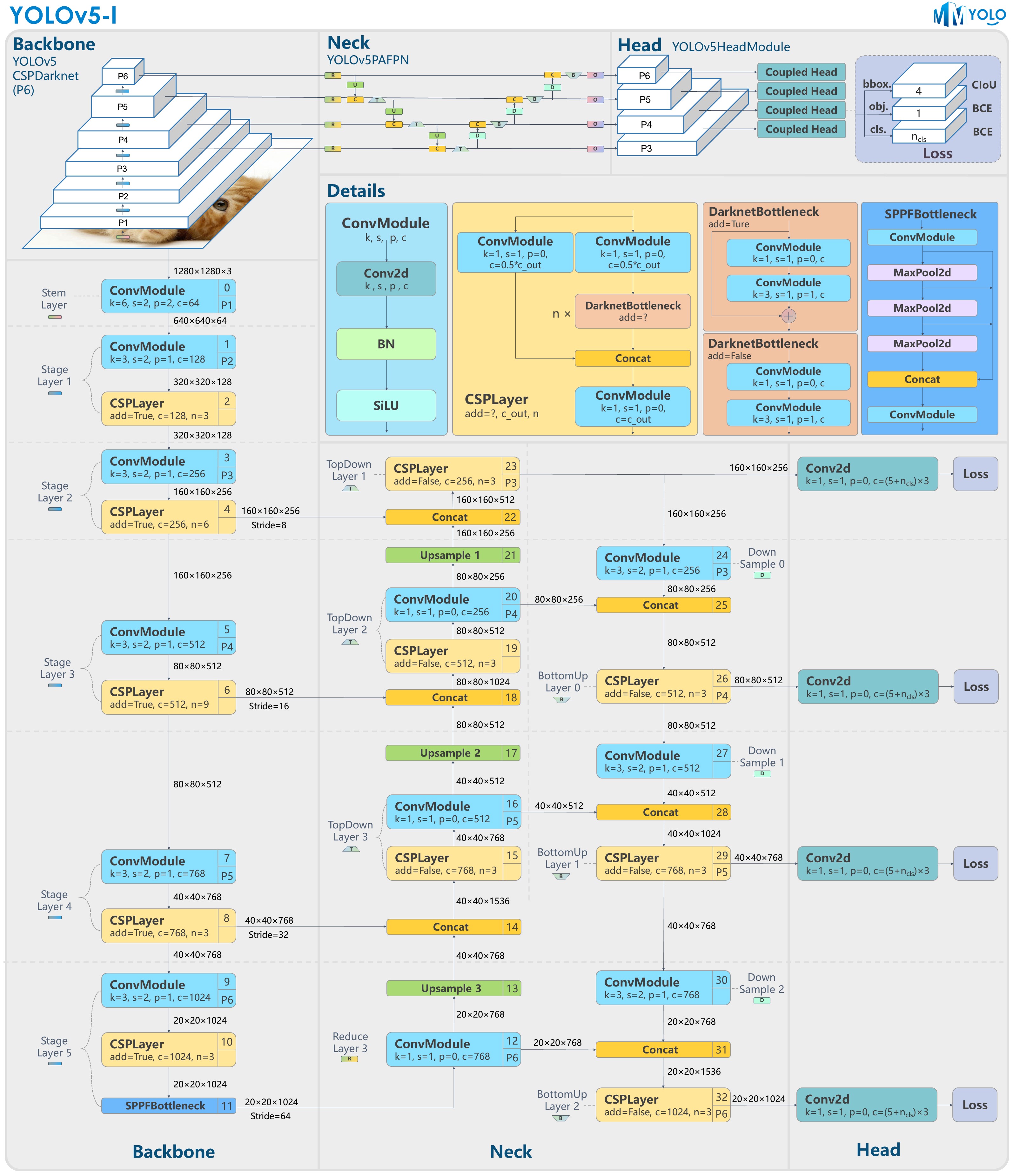 图 2:YOLOv5-l-P6 模型结构
图 2:YOLOv5-l-P6 模型结构
以上结构图由 RangeKing@github 绘制。
YOLOv5 是一个面向实时工业应用而开源的目标检测算法,受到了广泛关注。我们认为让 YOLOv5 爆火的原因不单纯在于 YOLOv5 算法本身的优异性,更多的在于开源库的实用和鲁棒性。简单来说 YOLOv5 开源库的主要特点为:
友好和完善的部署支持
算法训练速度极快,在 300 epoch 情况下训练时长和大部分 one-stage 算法如 RetinaNet、ATSS 和 two-stage 算法如 Faster R-CNN 在 12 epoch 的训练时间接近
框架进行了非常多的 corner case 优化,功能和文档也比较丰富
如图 1 和 2 所示,YOLOv5 的 P5 和 P6 版本主要差异在于网络结构和图片输入分辨率。其他区别,如 anchors 个数和 loss 权重可详见配置文件。本文将从 YOLOv5 算法本身原理讲起,然后重点分析 MMYOLO 中的实现。关于 YOLOv5 的使用指南和速度等对比请阅读本文的后续内容。
提示
没有特殊说明情况下,本文默认描述的是 P5 模型。
希望本文能够成为你入门和掌握 YOLOv5 的核心文档。由于 YOLOv5 本身也在不断迭代更新,我们也会不断的更新本文档。请注意阅读最新版本。
MMYOLO 实现配置:https://github.com/open-mmlab/mmyolo/blob/main/configs/yolov5/
YOLOv5 官方开源库地址:https://github.com/ultralytics/yolov5
1 v6.1 算法原理和 MMYOLO 实现解析¶
YOLOv5 官方 release 地址:https://github.com/ultralytics/yolov5/releases/tag/v6.1
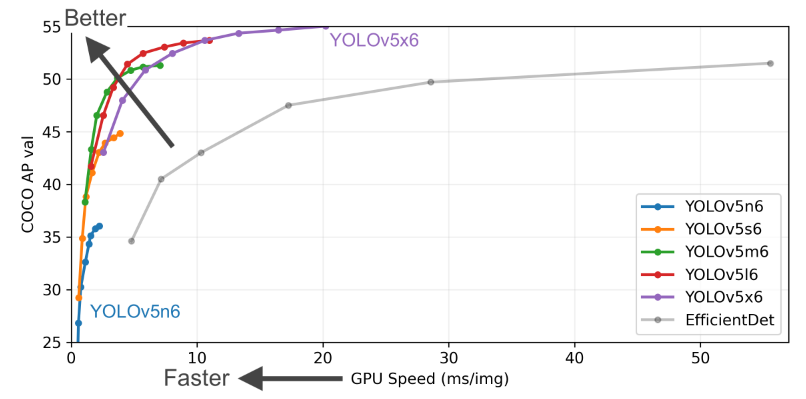
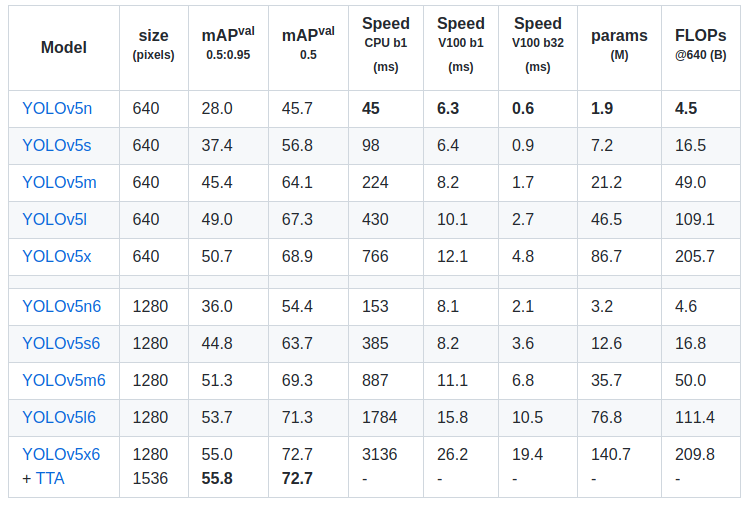
性能如上表所示。YOLOv5 有 P5 和 P6 两个不同训练输入尺度的模型,P6 即为 1280x1280 输入的大模型,通常用的是 P5 常规模型,输入尺寸是 640x640 。本文解读的也是 P5 模型结构。
通常来说,目标检测算法都可以分成数据增强、模型结构、loss 计算等组件,YOLOv5 也一样,如下所示:
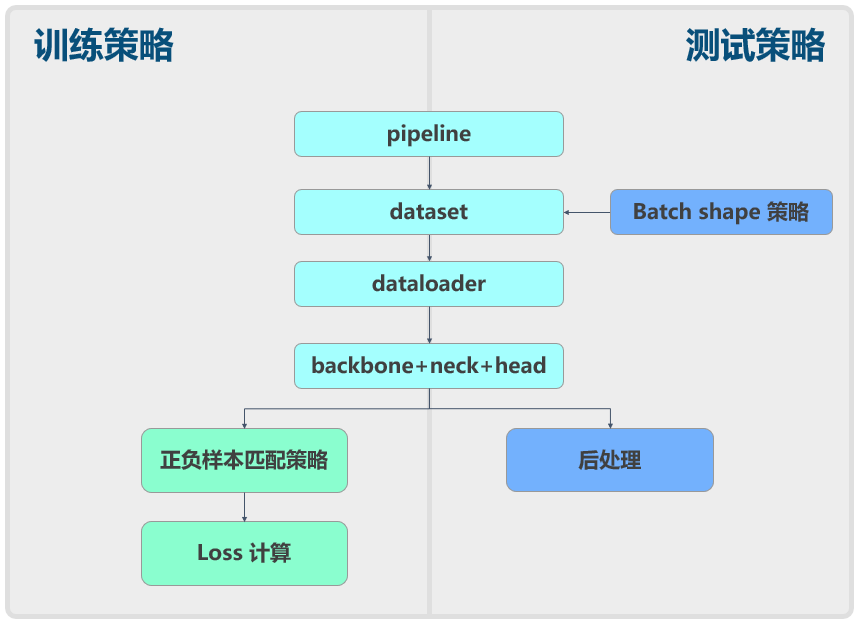
下面将从原理和结合 MMYOLO 的具体实现方面进行简要分析。
1.1 数据增强模块¶
YOLOv5 目标检测算法中使用的数据增强比较多,包括:
Mosaic 马赛克
RandomAffine 随机仿射变换
MixUp
图像模糊等采用 Albu 库实现的变换
HSV 颜色空间增强
随机水平翻转
其中 Mosaic 数据增强概率为 1,表示一定会触发,而对于 small 和 nano 两个版本的模型不使用 MixUp,其他的 l/m/x 系列模型则采用了 0.1 的概率触发 MixUp。小模型能力有限,一般不会采用 MixUp 等强数据增强策略。
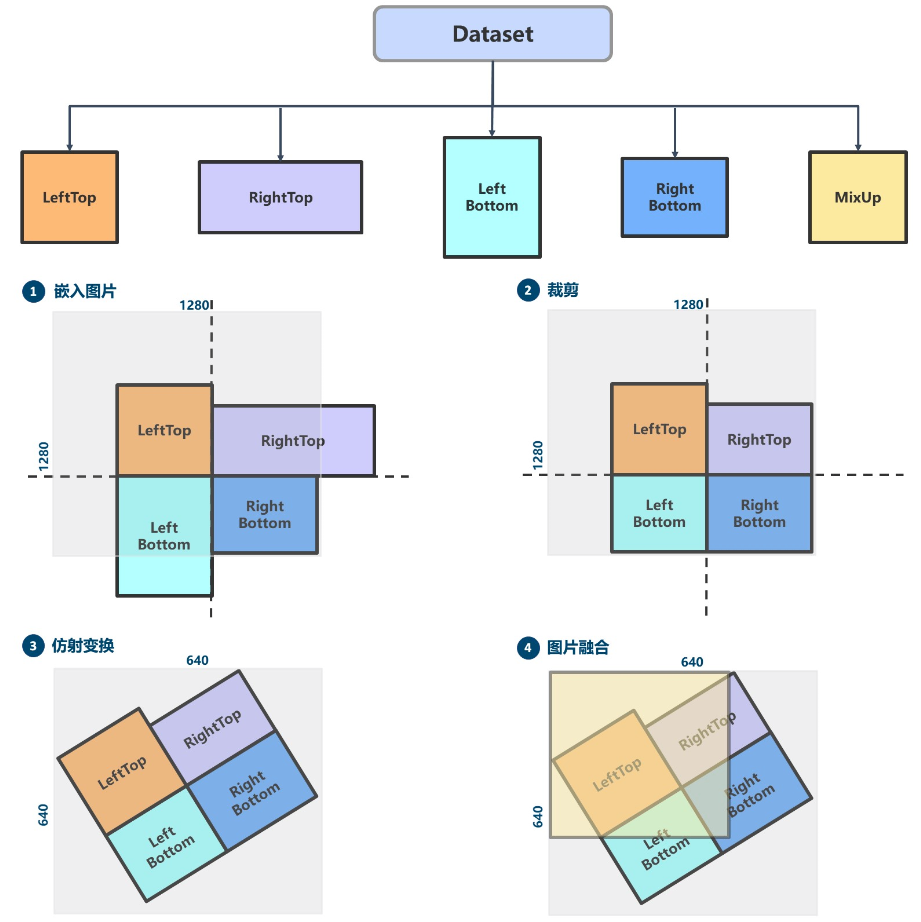
其核心的 Mosaic + RandomAffine + MixUp 过程简要绘制如下:
下面对其进行简要分析。
1.1.1 Mosaic 马赛克¶

Mosaic 属于混合类数据增强,因为它在运行时候需要 4 张图片拼接,变相的相当于增加了训练的 batch size。其运行过程简要概况为:
随机生成拼接后 4 张图的交接中心点坐标,此时就相当于确定了 4 张拼接图片的交接点
随机选出另外 3 张图片的索引以及读取对应的标注
对每张图片采用保持宽高比的 resize 操作将其缩放到指定大小
按照上下左右规则,计算每张图片在待输出图片中应该放置的位置,因为图片可能出界故还需要计算裁剪坐标
利用裁剪坐标将缩放后的图片裁剪,然后贴到前面计算出的位置,其余位置全部补 114 像素值
对每张图片的标注也进行相应处理
注意:由于拼接了 4 张图,所以输出图片面积会扩大 4 倍,从 640x640 变成 1280x1280,因此要想恢复为 640x640, 必须要再接一个 RandomAffine 随机仿射变换,否则图片面积就一直是扩大 4 倍的。
1.1.2 RandomAffine 随机仿射变换¶

随机仿射变换有两个目的:
对图片进行随机几何仿射变换
将 Mosaic 输出的扩大 4 倍的图片还原为 640x640 尺寸
随机仿射变换包括平移、旋转、缩放、错切等几何增强操作,同时由于 Mosaic 和 RandomAffine 属于比较强的增强操作,会引入较大噪声,因此需要对增强后的标注进行处理,过滤规则为:
增强后的 gt bbox 宽高要大于 wh_thr
增强后的 gt bbox 面积和增强前的 gt bbox 面积比要大于 ar_thr,防止增强太严重
最大宽高比要小于 area_thr,防止宽高比改变太多
由于旋转后标注框会变大导致不准确,因此目标检测里面很少会使用旋转数据增强。
1.1.3 MixUp¶
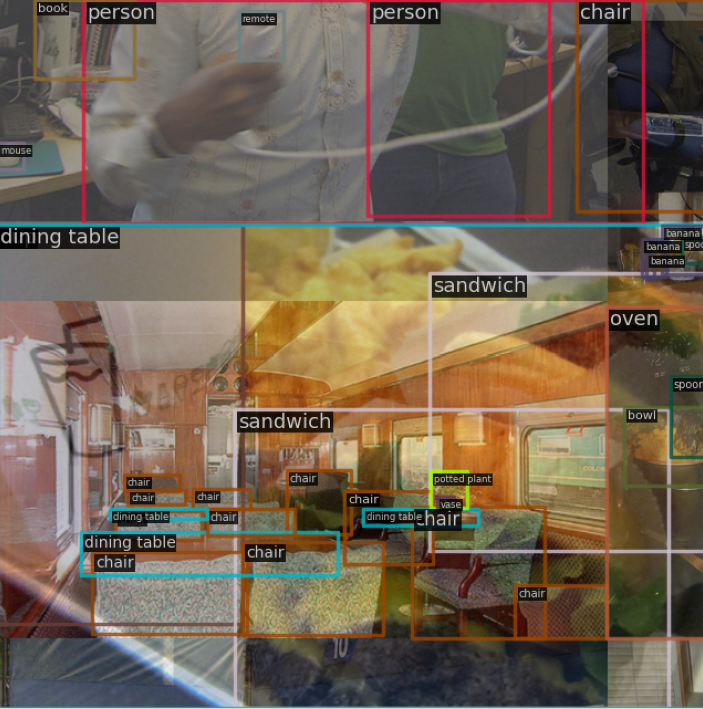
MixUp 和 Mosaic 类似也属于混合图片类增强方法。随机选出另外一张图后将两图再随机混合。具体实现方法有多种,常见的做法是要么将 label 直接拼接起来,要么将 label 也采用 alpha 方法混合。原作者的做法非常简单,对 label 即直接拼接,而图片通过分布采样混合。
需要特别注意的是: YOLOv5 实现的 MixUp 中,随机出来的另一张图也需要经过 Mosaic 马赛克 + RandomAffine 随机仿射变换 的增强后才能混合。这个和其他开源库实现可能不太一样。
1.1.4 图像模糊和其他数据增强策略¶

剩下的数据增强包括
图像模糊等采用 Albu 库实现的变换
HSV 颜色空间增强
随机水平翻转
MMDetection 开源库中已经对 Albu 第三方数据增强库进行了封装,使用户可以简单的通过配置即可使用 Albu 库中提供的任何数据增强功能。而 HSV 颜色空间增强和随机水平翻转都是属于比较常规的数据增强,不需要特殊介绍。
1.1.5 MMYOLO 实现解析¶
常规的单图数据增强例如随机翻转等比较容易实现,而 Mosaic 类的混合数据增强则不太容易。在 MMDetection 复现的 YOLOX 算法中提出了 MultiImageMixDataset 数据集包装器的概念,其实现过程如下:
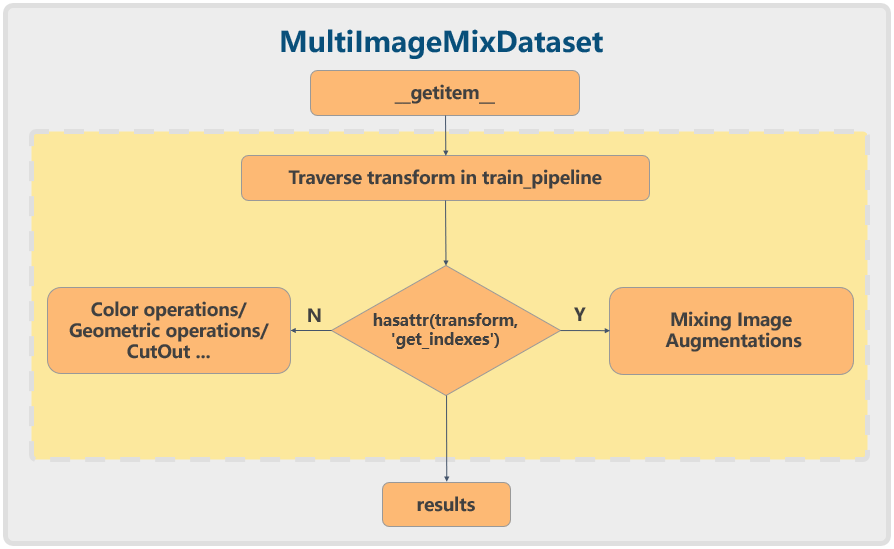
对于 Mosaic 等混合类数据增强策略,会需要额外实现一个 get_indexes 方法来获取其他图片索引,然后用得到的 4 张图片信息就可以进行 Mosaic 增强了。
以 MMDetection 中实现的 YOLOX 为例,其配置文件写法如下所示:
train_pipeline = [
dict(type='Mosaic', img_scale=img_scale, pad_val=114.0),
dict(
type='RandomAffine',
scaling_ratio_range=(0.1, 2),
border=(-img_scale[0] // 2, -img_scale[1] // 2)),
dict(
type='MixUp',
img_scale=img_scale,
ratio_range=(0.8, 1.6),
pad_val=114.0),
...
]
train_dataset = dict(
# use MultiImageMixDataset wrapper to support mosaic and mixup
type='MultiImageMixDataset',
dataset=dict(
type='CocoDataset',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True)
]),
pipeline=train_pipeline)
MultiImageMixDataset 数据集包装器传入一个包括 Mosaic 和 RandAffine 等数据增强,而 CocoDataset 中也需要传入一个包括图片和标注加载的 pipeline。通过这种方式就可以快速的实现混合类数据增强。
但是上述实现有一个缺点: 对于不熟悉 MMDetection 的用户来说,其经常会忘记 Mosaic 必须要和 MultiImageMixDataset 配合使用,否则会报错,而且这样会加大复杂度和理解难度。
为了解决这个问题,在 MMYOLO 中我们进一步进行了简化。直接让 pipeline 能够获取到 dataset 对象,此时就可以将 Mosaic 等混合类数据增强的实现和使用变成和随机翻转一样。 此时在 MMYOLO 中 YOLOX 的配置写法变成如下所示:
pre_transform = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True)
]
train_pipeline = [
*pre_transform,
dict(
type='Mosaic',
img_scale=img_scale,
pad_val=114.0,
pre_transform=pre_transform),
dict(
type='mmdet.RandomAffine',
scaling_ratio_range=(0.1, 2),
border=(-img_scale[0] // 2, -img_scale[1] // 2)),
dict(
type='YOLOXMixUp',
img_scale=img_scale,
ratio_range=(0.8, 1.6),
pad_val=114.0,
pre_transform=pre_transform),
...
]
这样就不再需要 MultiImageMixDataset 了,使用和理解上会更加简单。
回到 YOLOv5 配置上,因为 YOLOv5 实现的 MixUp 中,随机选出来的另一张图也需要经过 Mosaic 马赛克+RandomAffine 随机仿射变换 增强后才能混合,故YOLOv5-m 数据增强配置如下所示:
pre_transform = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True)
]
mosaic_transform= [
dict(
type='Mosaic',
img_scale=img_scale,
pad_val=114.0,
pre_transform=pre_transform),
dict(
type='YOLOv5RandomAffine',
max_rotate_degree=0.0,
max_shear_degree=0.0,
scaling_ratio_range=(0.1, 1.9), # scale = 0.9
border=(-img_scale[0] // 2, -img_scale[1] // 2),
border_val=(114, 114, 114))
]
train_pipeline = [
*pre_transform,
*mosaic_transform,
dict(
type='YOLOv5MixUp',
prob=0.1,
pre_transform=[
*pre_transform,
*mosaic_transform
]),
...
]
1.2 网络结构¶
本小结由 RangeKing@github 撰写,非常感谢!!!
YOLOv5 网络结构是标准的 CSPDarknet + PAFPN + 非解耦 Head。
YOLOv5 网络结构大小由 deepen_factor 和 widen_factor 两个参数决定。其中 deepen_factor 控制网络结构深度,即 CSPLayer 中 DarknetBottleneck 模块堆叠的数量;widen_factor 控制网络结构宽度,即模块输出特征图的通道数。以 YOLOv5-l 为例,其 deepen_factor = widen_factor = 1.0 。P5 和 P6 的模型整体结构分别如图 1 和图 2 所示。
图的上半部分为模型总览;下半部分为具体网络结构,其中的模块均标有序号,方便用户与 YOLOv5 官方仓库的配置文件对应;中间部分为各子模块的具体构成。
如果想使用 netron 可视化网络结构图细节,可以直接在 netron 中将 MMDeploy 导出的 ONNX 文件格式文件打开。
提示
1.2 小节涉及的特征维度(shape)都为 (B, C, H, W)。
1.2.1 Backbone¶
在 MMYOLO 中 CSPDarknet 继承自 BaseBackbone,整体结构和 ResNet 类似。P5 模型共 5 层结构,包含 1 个 Stem Layer 和 4 个 Stage Layer:
Stem Layer是 1 个 6x6 kernel 的ConvModule,相较于 v6.1 版本之前的Focus模块更加高效。除了最后一个
Stage Layer,其他均由 1 个ConvModule和 1 个CSPLayer组成。如上图 Details 部分所示。 其中ConvModule为 3x3的Conv2d+BatchNorm+SiLU 激活函数。CSPLayer即 YOLOv5 官方仓库中的 C3 模块,由 3 个ConvModule+ n 个DarknetBottleneck(带残差连接) 组成。最后一个
Stage Layer在最后增加了SPPF模块。SPPF模块是将输入串行通过多个 5x5 大小的MaxPool2d层,与SPP模块效果相同,但速度更快。P5 模型会在
Stage Layer2-4 之后分别输出一个特征图进入Neck结构。以 640x640 输入图片为例,其输出特征为 (B,256,80,80)、(B,512,40,40) 和 (B,1024,20,20),对应的 stride 分别为 8/16/32。P6 模型会在
Stage Layer2-5 之后分别输出一个特征图进入Neck结构。以 1280x1280 输入图片为例,其输出特征为 (B,256,160,160)、(B,512,80,80)、(B,768,40,40) 和 (B,1024,20,20),对应的 stride 分别为 8/16/32/64。
1.2.2 Neck¶
YOLOv5 官方仓库的配置文件中并没有 Neck 部分,为方便用户与其他目标检测网络结构相对应,我们将官方仓库的 Head 拆分成 PAFPN 和 Head 两部分。
基于 BaseYOLONeck 结构,YOLOv5 Neck 也是遵循同一套构建流程,对于不存在的模块,我们采用 nn.Identity 代替。
Neck 模块输出的特征图和 Backbone 完全一致。即 P5 模型为 (B,256,80,80)、 (B,512,40,40) 和 (B,1024,20,20);P6 模型为 (B,256,160,160)、(B,512,80,80)、(B,768,40,40) 和 (B,1024,20,20)。
1.2.3 Head¶
YOLOv5 Head 结构和 YOLOv3 完全一样,为 非解耦 Head。Head 模块只包括 3 个不共享权重的卷积,用于将输入特征图进行变换而已。
前面的 PAFPN 依然是输出 3 个不同尺度的特征图,shape 为 (B,256,80,80)、 (B,512,40,40) 和 (B,1024,20,20)。 由于 YOLOv5 是非解耦输出,即分类和 bbox 检测等都是在同一个卷积的不同通道中完成。以 COCO 80 类为例:
P5 模型在输入为 640x640 分辨率情况下,其 Head 模块输出的 shape 分别为
(B, 3x(4+1+80),80,80),(B, 3x(4+1+80),40,40)和(B, 3x(4+1+80),20,20)。P6 模型在输入为 1280x1280 分辨率情况下,其 Head 模块输出的 shape 分别为
(B, 3x(4+1+80),160,160),(B, 3x(4+1+80),80,80),(B, 3x(4+1+80),40,40)和(B, 3x(4+1+80),20,20)。 其中 3 表示 3 个 anchor,4 表示 bbox 预测分支,1 表示 obj 预测分支,80 表示 COCO 数据集类别预测分支。
1.3 正负样本匹配策略¶
正负样本匹配策略的核心是确定预测特征图的所有位置中哪些位置应该是正样本,哪些是负样本,甚至有些是忽略样本。 匹配策略是目标检测算法的核心,一个好的匹配策略可以显著提升算法性能。
YOLOV5 的匹配策略简单总结为:采用了 anchor 和 gt_bbox 的 shape 匹配度作为划分规则,同时引入跨邻域网格策略来增加正样本。 其主要包括如下两个核心步骤:
对于任何一个输出层,抛弃了常用的基于 Max IoU 匹配的规则,而是直接采用 shape 规则匹配,也就是该 GT Bbox 和当前层的 Anchor 计算宽高比,如果宽高比例大于设定阈值,则说明该 GT Bbox 和 Anchor 匹配度不够,将该 GT Bbox 暂时丢掉,在该层预测中该 GT Bbox 对应的网格内的预测位置认为是负样本
对于剩下的 GT Bbox(也就是匹配上的 GT Bbox),计算其落在哪个网格内,同时利用四舍五入规则,找出最近的两个网格,将这三个网格都认为是负责预测该 GT Bbox 的,可以粗略估计正样本数相比之前的 YOLO 系列,至少增加了三倍
下面会对每个部分进行详细说明,部分描述和图示直接或间接参考自官方 Repo。
1.3.1 Anchor 设置¶
YOLOv5 是 Anchor-based 的目标检测算法,其 Anchor size 的获取方式与 YOLOv3 类似,也是使用聚类获得,其不同之处在于聚类使用的标准不再是基于 IoU 的,而是使用形状上的宽高比作为聚类准则(即 shape-match )。
在用户更换了数据集后,可以使用 MMYOLO 里带有的 Anchor 分析工具,对自己的数据集进行分析,确定合适的 Anchor size。
python tools/analysis_tools/optimize_anchors.py ${CONFIG} --algorithm v5-k-means
--input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} --output-dir ${OUTPUT_DIR}
然后在 config 文件 里修改默认 Anchor size:
anchors = [[(10, 13), (16, 30), (33, 23)], [(30, 61), (62, 45), (59, 119)],
[(116, 90), (156, 198), (373, 326)]]
1.3.2 Bbox 编解码过程¶
在 Anchor-based 算法中,预测框通常会基于 Anchor 进行变换,然后预测变换量,这对应 GT Bbox 编码过程,而在预测后需要进行 Pred Bbox 解码,还原为真实尺度的 Bbox,这对应 Pred Bbox 解码过程。
在 YOLOv3 中,回归公式为:
公式中,
而在 YOLOv5 中,回归公式为:
改进之处主要有以下两点:
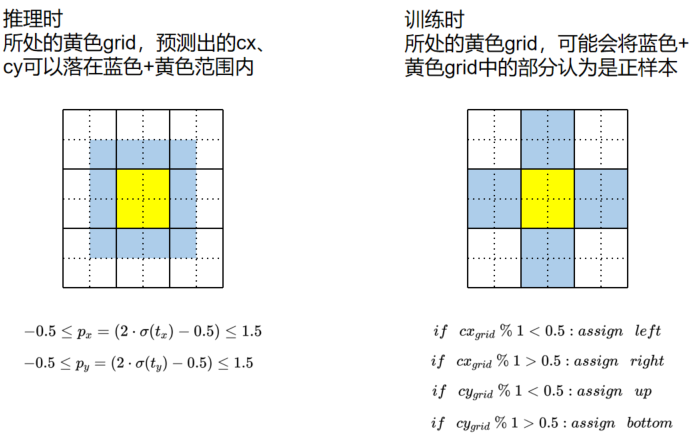
中心点坐标范围从 (0, 1) 调整至 (-0.5, 1.5)
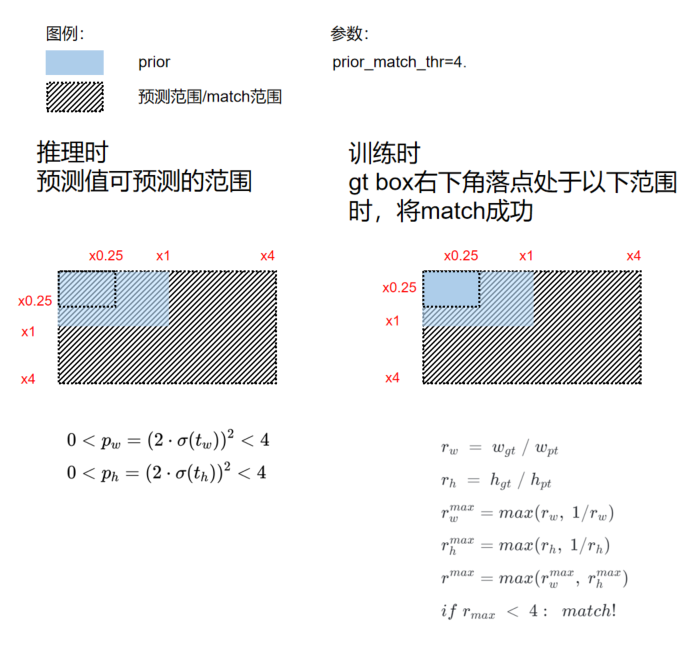
宽高范围从
调整至
这个改进具有以下好处:
新的中心点设置能更好的预测到 0 和 1。这有助于更精准回归出 box 坐标。
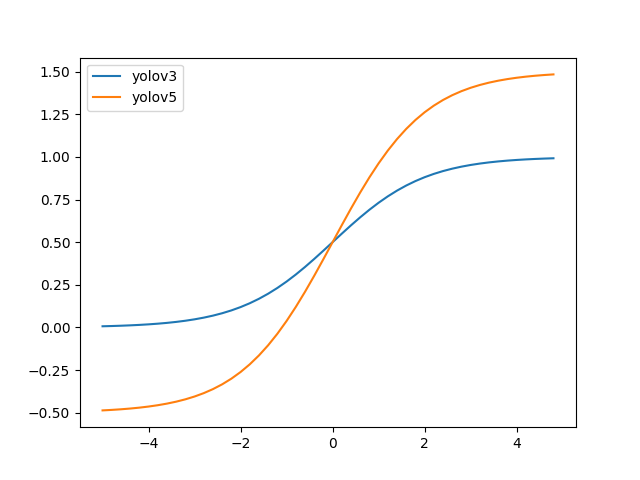
宽高回归公式中 exp(x) 是无界的,这会导致梯度失去控制,造成训练不稳定。YOLOv5 中改进后的宽高回归公式优化了此问题。
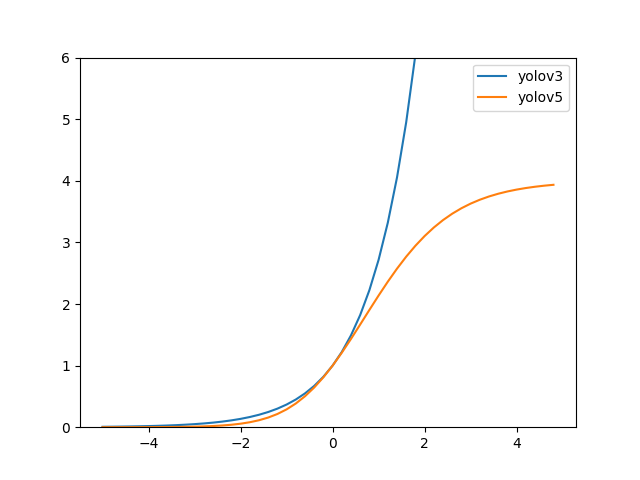
1.3.3 匹配策略¶
在 MMYOLO 设计中,无论网络是 Anchor-based 还是 Anchor-free,我们统一使用 prior 称呼 Anchor。
正样本匹配包含以下两步:
(1) “比例”比较
将 GT Bbox 的 WH 与 Prior 的 WH 进行“比例”比较。
比较流程:
此处我们用一个 GT Bbox 与 P3 特征图的 Prior 进行匹配的案例进行讲解和图示:
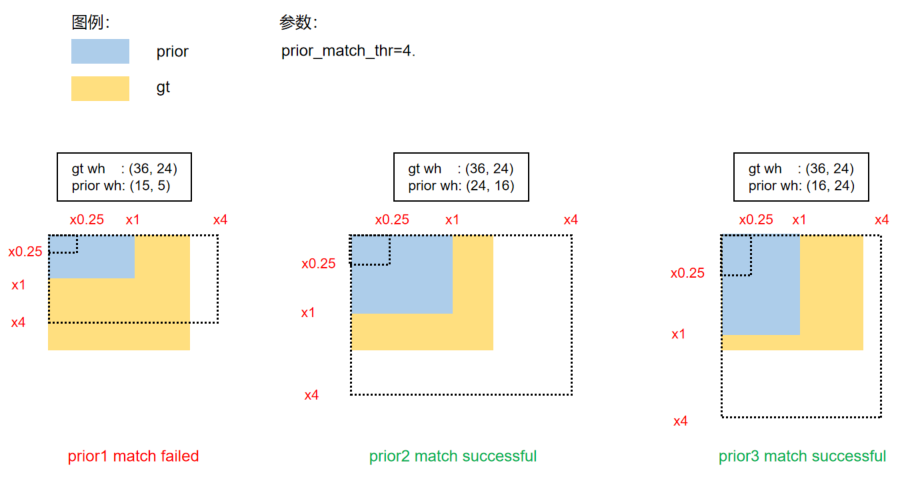
prior1 匹配失败的原因是
(2) 为步骤 1 中 match 的 GT 分配对应的正样本
依然沿用上面的例子:
GT Bbox (cx, cy, w, h) 值为 (26, 37, 36, 24),
Prior WH 值为 [(15, 5), (24, 16), (16, 24)],在 P3 特征图上,stride 为 8。通过计算,prior2 和 prior3 能够 match。
计算过程如下:
(2.1) 将 GT Bbox 的中心点坐标对应到 P3 的 grid 上
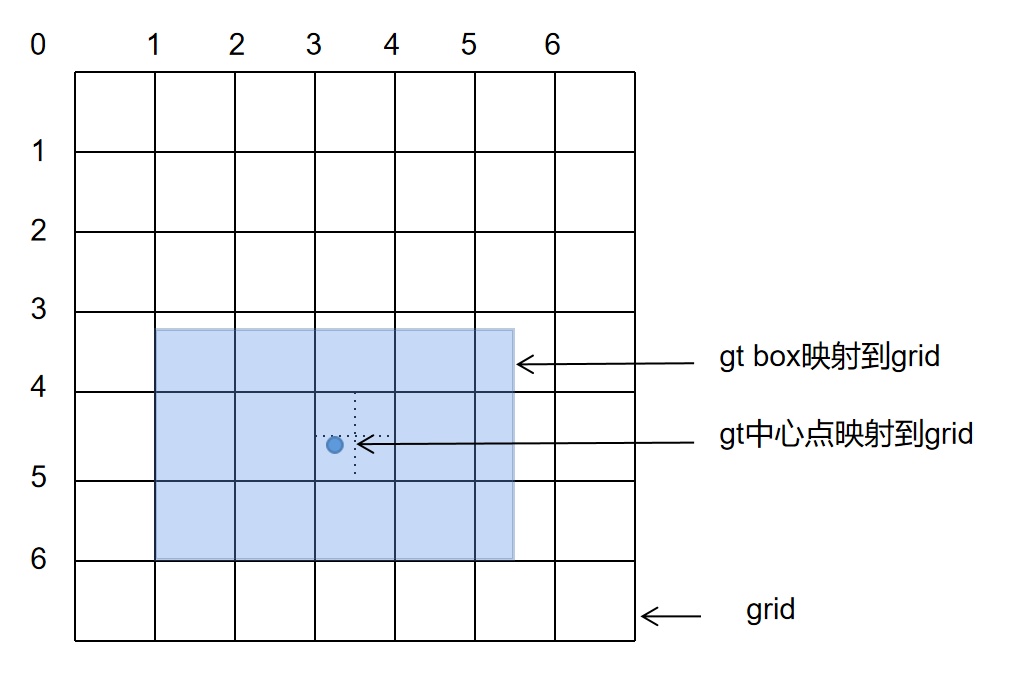
(2.2) 将 GT Bbox 中心点所在的 grid 分成四个象限,由于中心点落在了左下角的象限当中,那么会将物体的左、下两个 grid 也认为是正样本
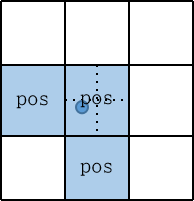
下图展示中心点落到不同位置时的正样本分配情况:
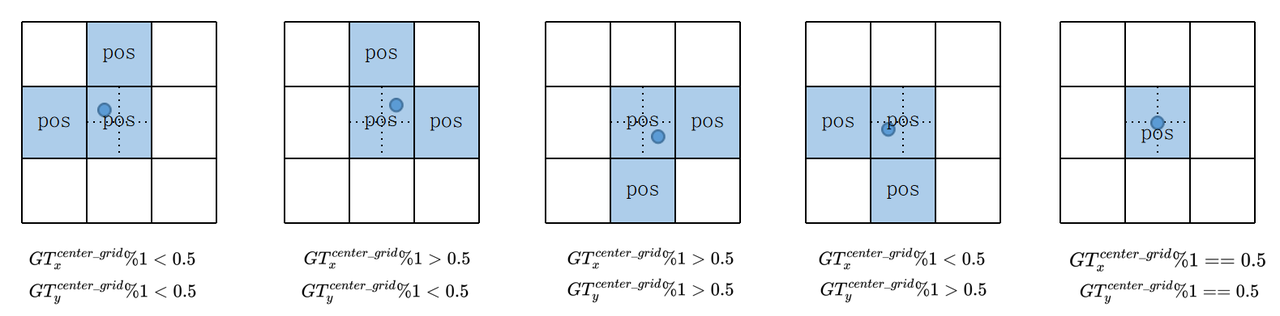
那么 YOLOv5 的 Assign 方式具体带来了哪些改进?
一个 GT Bbox 能够匹配多个 Prior
一个 GT Bbox 和一个Prior 匹配时,能分配 1-3 个正样本
以上策略能适度缓解目标检测中常见的正负样本不均衡问题。
而 YOLOv5 中的回归方式,和 Assign 方式是相互呼应的:
中心点回归方式:
WH 回归方式:
1.4 Loss 设计¶
YOLOv5 中总共包含 3 个 Loss,分别为:
Classes loss:使用的是 BCE loss
Objectness loss:使用的是 BCE loss
Location loss:使用的是 CIoU loss
三个 loss 按照一定比例汇总:
P3、P4、P5 层对应的 Objectness loss 按照不同权重进行相加,默认的设置是
obj_level_weights=[4., 1., 0.4]
在复现中我们发现 YOLOv5 中使用的 CIoU 与目前最新官方 CIoU 存在一定的差距,差距体现在 alpha 参数的计算。
官方版本:
参考资料:https://github.com/Zzh-tju/CIoU/blob/master/layers/modules/multibox_loss.py#L53-L55
alpha = (ious > 0.5).float() * v / (1 - ious + v)
YOLOv5 版本:
alpha = v / (v - ious + (1 + eps))
这是一个有趣的细节,后续需要测试不同 alpha 计算方式情况下带来的精度差距。
1.5 优化策略和训练过程¶
YOLOv5 对每个优化器的参数组进行非常精细的控制,简单来说包括如下部分。
1.5.1 优化器分组¶
将优化参数分成 Conv/Bias/BN 三组,在 WarmUp 阶段,不同组采用不同的 lr 以及 momentum 更新曲线。 同时在 WarmUp 阶段采用的是 iter-based 更新策略,而在非 WarmUp 阶段则变成 epoch-based 更新策略,可谓是 trick 十足。
MMYOLO 中是采用 YOLOv5OptimizerConstructor 优化器构造器实现优化器参数分组。优化器构造器的作用就是对一些特殊的参数组初始化过程进行精细化控制,因此可以很好的满足需求。
而不同的参数组采用不同的调度曲线功能则是通过 YOLOv5ParamSchedulerHook 实现。而不同的参数组采用不同的调度曲线功能则是通过 YOLOv5ParamSchedulerHook 实现。
1.5.2 weight decay 参数自适应¶
作者针对不同的 batch size 采用了不同的 weight decay 策略,具体来说为:
当训练 batch size <= 64 时,weight decay 不变
当训练 batch size > 64 时,weight decay 会根据总 batch size 进行线性缩放
MMYOLO 也是通过 YOLOv5OptimizerConstructor 实现。
1.5.3 梯度累加¶
为了最大化不同 batch size 情况下的性能,作者设置总 batch size 小于 64 时候会自动开启梯度累加功能。
训练过程和大部分 YOLO 类似,包括如下策略:
没有使用预训练权重
没有采用多尺度训练策略,同时可以开启 cudnn.benchmark 进一步加速训练
使用了 EMA 策略平滑模型
默认采用 AMP 自动混合精度训练
需要特意说明的是:YOLOv5 官方对于 small 模型是采用单卡 v100 训练,bs 为 128,而 m/l/x 等是采用不同数目的多卡实现的, 这种训练策略不太规范,为此在 MMYOLO 中全部采用了 8 卡,每卡 16 bs 的设置,同时为了避免性能差异,训练时候开启了 SyncBN。
1.6 推理和后处理过程¶
YOLOv5 后处理过程和 YOLOv3 非常类似,实际上 YOLO 系列的后处理逻辑都是类似的。
1.6.1 核心控制参数¶
multi_label
对于多类别预测来说需要考虑是否是多标签任务,也就是同一个预测位置会预测的多个类别概率,和是否当作单类处理。因为 YOLOv5 采用 sigmoid 预测模式,在考虑多标签情况下可能会出现一个物体检测出两个不同类别的框,这有助于评估指标 mAP,但是不利于实际应用。 因此在需要算评估指标时候 multi_label 是 True,而推理或者实际应用时候是 False
score_thr 和 nms_thr
score_thr 阈值用于过滤类别分值,低于分值的检测框当做背景处理,nms_thr 是 nms 时阈值。同样的,在计算评估指标 mAP 阶段可以将 score_thr 设置的非常低,这通常能够提高召回率,从而提升 mAP,但是对于实际应用来说没有意义,且会导致推理过程极慢。为此在测试和推理阶段会设置不同的阈值
nms_pre 和 max_per_img
nms_pre 表示 nms 前的最大保留检测框数目,这通常是为了防止 nms 运行时候输入框过多导致速度过慢问题,默认值是 30000。 max_per_img 表示最终保留的最大检测框数目,通常设置为 300。
以 COCO 80 类为例,假设输入图片大小为 640x640
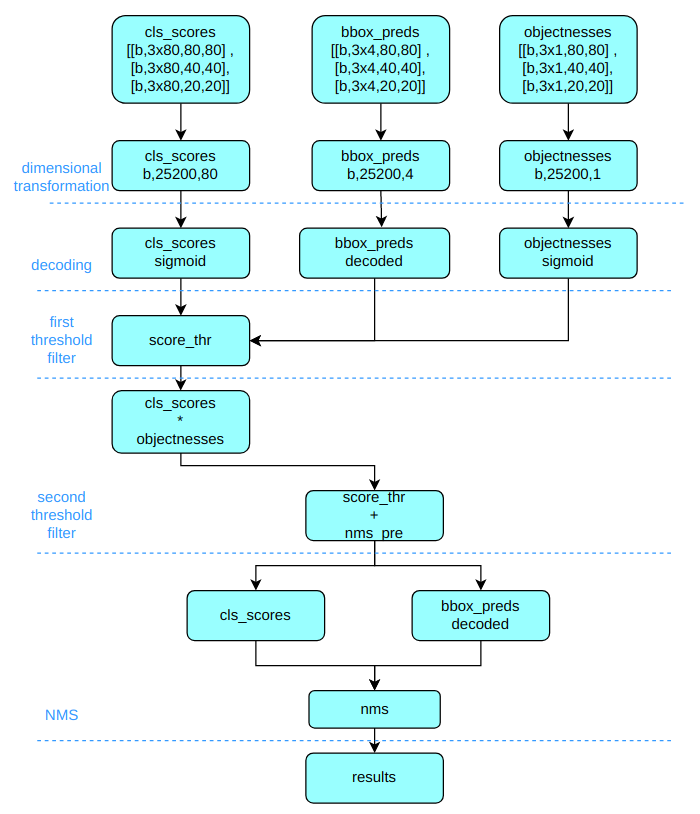
其推理和后处理过程为:
(1) 维度变换
YOLOv5 输出特征图尺度为 80x80、40x40 和 20x20 的三个特征图,每个位置共 3 个 anchor,因此输出特征图通道为 3x(5+80)=255。 YOLOv5 是非解耦输出头,而其他大部分算法都是解耦输出头,为了统一后处理逻辑,我们提前将其进行解耦,分成了类别预测分支、bbox 预测分支和 obj 预测分支。
将三个不同尺度的类别预测分支、bbox 预测分支和 obj 预测分支进行拼接,并进行维度变换。为了后续方便处理,会将原先的通道维度置换到最后,类别预测分支、bbox 预测分支和 obj 预测分支的 shape 分别为 (b, 3x80x80+3x40x40+3x20x20, 80)=(b,25200,80),(b,25200,4),(b,25200,1)。
(2) 解码还原到原图尺度
分类预测分支和 obj 分支需要进行 sigmoid 计算,而 bbox 预测分支需要进行解码,还原为真实的原图解码后 xyxy 格式
(3) 第一次阈值过滤
遍历 batch 中的每张图,然后用 score_thr 对类别预测分值进行阈值过滤,去掉低于 score_thr 的预测结果
(4) 第二次阈值过滤
将 obj 预测分值和过滤后的类别预测分值相乘,然后依然采用 score_thr 进行阈值过滤。 在这过程中还需要考虑 multi_label 和 nms_pre,确保过滤后的检测框数目不会多于 nms_pre。
(5) 还原到原图尺度和 nms
基于前处理过程,将剩下的检测框还原到网络输出前的原图尺度,然后进行 nms 即可。最终输出的检测框不能多于 max_per_img。
1.6.2 batch shape 策略¶
为了加速验证集的推理过程,作者提出了 batch shape 策略,其核心原则是:确保在 batch 推理过程中同一个 batch 内的图片 pad 像素最少,不要求整个验证过程中所有 batch 的图片尺度一样。
其大概流程是:将整个测试或者验证数据的宽高比进行排序,然后依据 batch 设置将排序后的图片组成一个 batch, 同时计算这个 batch 内最佳的 batch shape,防止 pad 像素过多。最佳 batch shape 计算原则为在保持宽高比的情况下进行 pad,不追求正方形图片输出。
image_shapes = []
for data_info in data_list:
image_shapes.append((data_info['width'], data_info['height']))
image_shapes = np.array(image_shapes, dtype=np.float64)
n = len(image_shapes) # number of images
batch_index = np.floor(np.arange(n) / self.batch_size).astype(
np.int64) # batch index
number_of_batches = batch_index[-1] + 1 # number of batches
aspect_ratio = image_shapes[:, 1] / image_shapes[:, 0] # aspect ratio
irect = aspect_ratio.argsort()
data_list = [data_list[i] for i in irect]
aspect_ratio = aspect_ratio[irect]
# Set training image shapes
shapes = [[1, 1]] * number_of_batches
for i in range(number_of_batches):
aspect_ratio_index = aspect_ratio[batch_index == i]
min_index, max_index = aspect_ratio_index.min(
), aspect_ratio_index.max()
if max_index < 1:
shapes[i] = [max_index, 1]
elif min_index > 1:
shapes[i] = [1, 1 / min_index]
batch_shapes = np.ceil(
np.array(shapes) * self.img_size / self.size_divisor +
self.pad).astype(np.int64) * self.size_divisor
for i, data_info in enumerate(data_list):
data_info['batch_shape'] = batch_shapes[batch_index[i]]
2 总结¶
本文对 YOLOv5 原理和在 MMYOLO 实现进行了详细解析,希望能帮助用户理解算法实现过程。同时请注意:由于 YOLOv5 本身也在不断更新,本开源库也会不断迭代,请及时阅读和同步最新版本。