YOLOv6 原理和实现全解析¶
0 简介¶
 图 1:YOLOv6-S 模型结构
图 1:YOLOv6-S 模型结构
 图 2:YOLOv6-L 模型结构
图 2:YOLOv6-L 模型结构
以上结构图由 wzr-skn@github 绘制。
YOLOv6 提出了一系列适用于各种工业场景的模型,包括 N/T/S/M/L,考虑到模型的大小,其架构有所不同,以获得更好的精度-速度权衡。本算法专注于检测的精度和推理效率,并在网络结构、训练策略等算法层面进行了多项改进和优化。
简单来说 YOLOv6 开源库的主要特点为:
统一设计了更高效的 Backbone 和 Neck:受到硬件感知神经网络设计思想的启发,基于 RepVGG style 设计了可重参数化、更高效的骨干网络 EfficientRep Backbone 和 Rep-PAN Neck。
相比于 YOLOX 的 Decoupled Head,进一步优化设计了简洁有效的 Efficient Decoupled Head,在维持精度的同时,降低了一般解耦头带来的额外延时开销。
在训练策略上,采用 Anchor-free 的策略,同时辅以 SimOTA 标签分配策略以及 SIoU 边界框回归损失来进一步提高检测精度。
本文将从 YOLOv6 算法本身原理讲起,然后重点分析 MMYOLO 中的实现。关于 YOLOv6 的使用指南和速度等对比请阅读本文的后续内容。
希望本文能够成为你入门和掌握 YOLOv6 的核心文档。由于 YOLOv6 本身也在不断迭代更新,我们也会不断的更新本文档。请注意阅读最新版本。
MMYOLO 实现配置:https://github.com/open-mmlab/mmyolo/blob/main/configs/yolov6/
YOLOv6 官方开源库地址:https://github.com/meituan/YOLOv6
1 YOLOv6 2.0 算法原理和 MMYOLO 实现解析¶
YOLOv6 2.0 官方 release 地址:https://github.com/meituan/YOLOv6/releases/tag/0.2.0


YOLOv6 和 YOLOv5 一样也可以分成数据增强、模型结构、loss 计算等组件,如下所示:
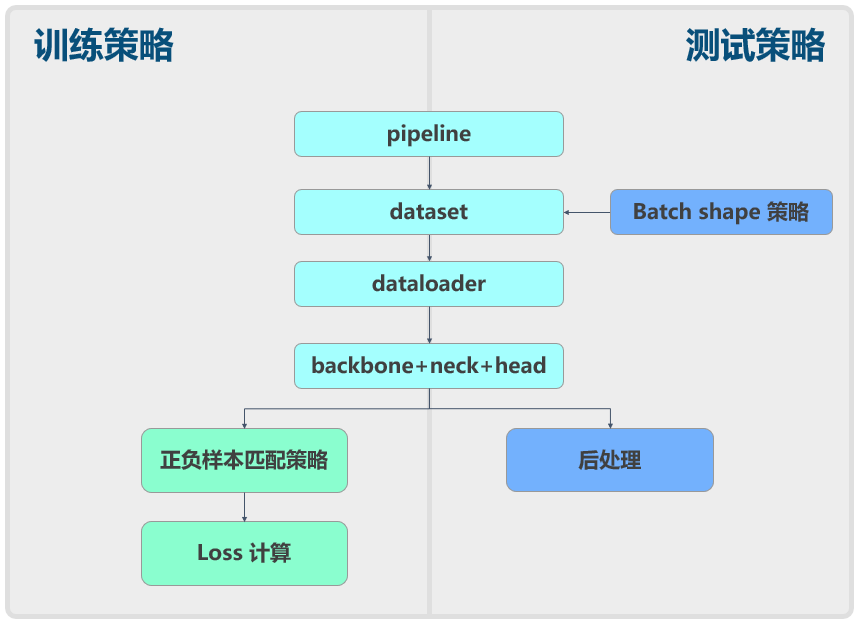
下面将从原理和结合 MMYOLO 的具体实现方面进行简要分析。
1.1 数据增强模块¶
YOLOv6 目标检测算法中使用的数据增强与 YOLOv5 基本一致,唯独不一样的是没有使用 Albu 的数据增强方式:
Mosaic 马赛克
RandomAffine 随机仿射变换
MixUp
~~图像模糊等采用 Albu 库实现的变换~~
HSV 颜色空间增强
随机水平翻转
关于每一个增强的详细解释,详情请看 YOLOv5 数据增强模块
另外,YOLOv6 参考了 YOLOX 的数据增强方式,分为 2 种增强方法组,一开始和 YOLOv5 一致,但是在最后 15 个 epoch 的时候将 Mosaic 使用 YOLOv5KeepRatioResize + LetterResize 替代了,个人感觉是为了拟合真实情况。
1.2 网络结构¶
YOLOv6 N/T/S 模型的网络结构由 EfficientRep + Rep-PAN + Efficient decoupled Head 构成,M/L 模型的网络结构则由 CSPBep + CSPRepPAFPN + Efficient decoupled Head 构成。其中,Backbone 和 Neck 部分的结构与 YOLOv5 较为相似,但不同的是其采用了重参数化结构 RepVGG Block 替换掉了原本的 ConvModule,在此基础上,将 CSPLayer 改进为了多个 RepVGG 堆叠的 RepStageBlock(N/T/S 模型)或 BepC3StageBlock(M/L 模型);Head 部分则参考了 FCOS 和 YOLOX 的检测头,将回归与分类分支解耦成两个分支进行预测。YOLOv6-S 和 YOLOv6-L 整体结构分别如图 1 和图 2 所示。
1.2.1 Backbone¶
已有研究表明,多分支的网络结构通常比单分支网络性能更加优异,例如 YOLOv5 的 CSPDarknet,但是这种结构会导致并行度降低进而增加推理延时;相反,类似于 VGG 的单分支网络则具有并行度高、内存占用小的优点,因此推理效率更高。而 RepVGG 则同时具备上述两种结构的优点,在训练时可解耦成多分支拓扑结构提升模型精度,实际部署时可等效融合为单个 3×3 卷积提升推理速度,RepVGG 示意图如下。因此,YOLOv6 基于 RepVGG 重参数化结构设计了高效的骨干网络 EfficientRep 和 CSPBep,其可以充分利用硬件算力,提升模型表征能力的同时降低推理延时。

在 N/T/S 模型中,YOLOv6 使用了 EfficientRep 作为骨干网络,其包含 1 个 Stem Layer 和 4 个 Stage Layer,具体细节如下:
Stem Layer中采用 stride=2 的RepVGGBlock替换了 stride=2 的 6×6ConvModule。Stage Layer结构与 YOLOv5 基本相似,将每个Stage layer的 1 个ConvModule和 1 个CSPLayer分别替换为 1 个RepVGGBlock和 1 个RepStageBlock,如上图 Details 部分所示。其中,第一个RepVGGBlock会做下采样和Channel维度变换,而每个RepStageBlock则由 n 个RepVGGBlock组成。此外,仍然在第 4 个Stage Layer最后增加SPPF模块后输出。
在 M/L 模型中,由于模型容量进一步增大,直接使用多个 RepVGGBlock 堆叠的 RepStageBlock 结构计算量和参数量呈现指数增长。因此,为了权衡计算负担和模型精度,在 M/L 模型中使用了 CSPBep 骨干网络,其采用 BepC3StageBlock 替换了小模型中的 RepStageBlock 。如下图所示,BepC3StageBlock 由 3 个 1×1 的 ConvModule 和多个子块(每个子块由两个 RepVGGBlock 残差连接)组成。

1.2.2 Neck¶
Neck 部分结构仍然在 YOLOv5 基础上进行了模块的改动,同样采用 RepStageBlock 或 BepC3StageBlock 对原本的 CSPLayer 进行了替换,需要注意的是,Neck 中 Down Sample 部分仍然使用了 stride=2 的 3×3 ConvModule,而不是像 Backbone 一样替换为 RepVGGBlock。
1.2.3 Head¶
不同于传统的 YOLO 系列检测头,YOLOv6 参考了 FCOS 和 YOLOX 中的做法,将分类和回归分支解耦成两个分支进行预测并且去掉了 obj 分支。同时,采用了 hybrid-channel 策略构建了更高效的解耦检测头,将中间 3×3 的 ConvModule 减少为 1 个,在维持精度的同时进一步减少了模型耗费,降低了推理延时。此外,需要说明的是,YOLOv6 在 Backobone 和 Neck 部分使用的激活函数是 ReLU,而在 Head 部分则使用的是 SiLU。
由于 YOLOv6 是解耦输出,分类和 bbox 检测通过不同卷积完成。以 COCO 80 类为例:
P5 模型在输入为 640x640 分辨率情况下,其 Head 模块输出的 shape 分别为
(B,4,80,80),(B,80,80,80),(B,4,40,40),(B,80,40,40),(B,4,20,20),(B,80,20,20)。
1.3 正负样本匹配策略¶
YOLOv6 采用的标签匹配策略与 TOOD
相同, 前 4 个 epoch 采用 ATSSAssigner 作为标签匹配策略的 warm-up ,
后续使用 TaskAlignedAssigner 算法选择正负样本, 基于官方开源代码, MMYOLO 中也对两个 assigner 算法进行了优化, 改进为 Batch 维度进行计算,
能够一定程度的加快速度。 下面会对每个部分进行详细说明。
1.3.1 Anchor 设置¶
YOLOv6 采用与 YOLOX 一样的 Anchor-free 无锚范式,省略了聚类和繁琐的 Anchor 超参设定,泛化能力强,解码逻辑简单。在训练的过程中会根据 feature size 去自动生成先验框。
使用 mmdet.MlvlPointGenerator 生成 anchor points。
prior_generator: ConfigType = dict(
type='mmdet.MlvlPointGenerator',
offset=0.5, # 网格中心点
strides=[8, 16, 32]) ,
# 调用生成多层 anchor points: list[torch.Tensor]
# 每一层都是 (featrue_h*feature_w,4), 4 表示 (x,y,stride_h,stride_w)
self.mlvl_priors = self.prior_generator.grid_priors(
self.featmap_sizes,
with_stride=True)
1.3.2 Bbox 编解码过程¶
YOLOv6 的 BBox Coder 采用的是 DistancePointBBoxCoder。
网络 bbox 预测的值为 (top, bottom, left, right),解码器将 anchor point 通过四个距离解码到坐标 (x1,y1,x2,y2)。
MMYOLO 中解码的核心源码:
def decode(points: torch.Tensor, pred_bboxes: torch.Tensor, stride: torch.Tensor) -> torch.Tensor:
"""
将预测值解码转化 bbox 的 xyxy
points (Tensor): 生成的 anchor point [x, y],Shape (B, N, 2) or (N, 2).
pred_bboxes (Tensor): 预测距离四边的距离。(left, top, right, bottom). Shape (B, N, 4) or (N, 4)
stride (Tensor): 特征图下采样倍率.
"""
# 首先将预测值转化为原图尺度
distance = pred_bboxes * stride[None, :, None]
# 根据点以及到四条边距离转为 bbox 的 x1y1x2y2
x1 = points[..., 0] - distance[..., 0]
y1 = points[..., 1] - distance[..., 1]
x2 = points[..., 0] + distance[..., 2]
y2 = points[..., 1] + distance[..., 3]
bboxes = torch.stack([x1, y1, x2, y2], -1)
return bboxes
1.3.3 匹配策略¶
0 <= epoch < 4,使用
BatchATSSAssignerepoch >= 4,使用
BatchTaskAlignedAssigner
ATSSAssigner¶
ATSSAssigner 是 ATSS 中提出的标签匹配策略。 ATSS 的匹配策略简单总结为:通过中心点距离先验对样本进行初筛,然后自适应生成 IoU 阈值筛选正样本。 YOLOv6 的实现种主要包括如下三个核心步骤:
因为 YOLOv6 是 Anchor-free,所以首先将
anchor point转化为大小为5*strdie的anchor。对于每一个
GT,在FPN的每一个特征层上, 计算与该层所有anchor中心点距离(位置先验), 然后优先选取距离topK近的样本,作为 初筛样本。对于每一个
GT,计算其 初筛样本 的IoU的均值mean与标准差std,将mean + std作为该GT的正样本的 自适应 IoU 阈值 ,大于该 自适应阈值 且中心点在GT内部的anchor才作为正样本,使得样本能够被assign到合适的FPN特征层上。
下图中,(a) 所示中等大小物体被 assign 到 FPN 的中层,(b) 所示偏大的物体被 assign 到 FPN 中检测大物体和偏大物体的两个层。

# 1. 首先将anchor points 转化为 anchors
# priors为(point_x,point_y,stride_w,stride_h), shape 为(N,4)
cell_half_size = priors[:, 2:] * 2.5
priors_gen = torch.zeros_like(priors)
priors_gen[:, :2] = priors[:, :2] - cell_half_size
priors_gen[:, 2:] = priors[:, :2] + cell_half_size
priors = priors_gen
# 2. 计算 anchors 与 GT 的 IoU
overlaps = self.iou_calculator(gt_bboxes.reshape([-1, 4]), priors)
# 3. 计算 anchor 与 GT 的中心距离
distances, priors_points = bbox_center_distance(
gt_bboxes.reshape([-1, 4]), priors)
# 4. 根据中心点距离,在 FPN 的每一层选取 TopK 临近的样本作为初筛样本
is_in_candidate, candidate_idxs = self.select_topk_candidates(
distances, num_level_priors, pad_bbox_flag)
# 5. 对于每一个 GT 计算其对应初筛样本的均值与标准差的和, 作为该GT的样本阈值
overlaps_thr_per_gt, iou_candidates = self.threshold_calculator(
is_in_candidate, candidate_idxs, overlaps, num_priors, batch_size,
num_gt)
# 6. 筛选大于阈值的样本作为正样本
is_pos = torch.where(
iou_candidates > overlaps_thr_per_gt.repeat([1, 1, num_priors]),
is_in_candidate, torch.zeros_like(is_in_candidate))
# 6. 保证样本中心点在 GT 内部且不超图像边界
pos_mask = is_pos * is_in_gts * pad_bbox_flag
TaskAlignedAssigner¶
TaskAlignedAssigner 是 TOOD 中提出的一种动态样本匹配策略。
由于 ATSSAssigner 是属于静态标签匹配策略,其选取正样本的策略主要根据 anchor 的位置进行挑选,
并不会随着网络的优化而选取到更好的样本。在目标检测中,分类和回归的任务最终作用于同一个目标,所以
TaskAlignedAssigner 认为样本的选取应该更加关注到对分类以及回归都友好的样本点。
TaskAlignedAssigner 的匹配策略简单总结为: 根据分类与回归的分数加权的分数选择正样本。
对于每一个
GT,对所有的预测框基于 GT类别对应分类分数 与 预测框与 GT 的 IoU 的加权得到一个关联分类以及回归的对齐分数alignment_metrics。对于每一个
GT,直接基于alignment_metrics对齐分数选取topK大的作为正样本。
因为在网络初期参数随机, 分类分数 和 预测框与 GT 的 IoU 都不准确,所以需要经过前 4 个 epoch 的 ATSSAssigner
的 warm-up。经过预热之后的 TaskAlignedAssigner 标签匹配策略就不使用中心距离的先验,
而是直接对每一个GT 选取 alignment_metrics 中 topK 大的样本作为正样本。
# 1. 基于分类分数与回归的 IoU 计算对齐分数 alignment_metrics
alignment_metrics = bbox_scores.pow(self.alpha) * overlaps.pow(
self.beta)
# 2. 保证中心点在 GT 内部的 mask
is_in_gts = select_candidates_in_gts(priors, gt_bboxes)
# 3. 选取 TopK 大的对齐分数的样本
topk_metric = self.select_topk_candidates(
alignment_metrics * is_in_gts,
topk_mask=pad_bbox_flag.repeat([1, 1, self.topk]).bool())
1.4 Loss 设计¶
参与 Loss 计算的共有两个值:loss_cls 和 loss_bbox,其各自使用的 Loss 方法如下:
Classes loss:使用的是
mmdet.VarifocalLossBBox loss:l/m/s使用的是
GIoULoss, t/n 用的是SIoULoss
权重比例是:loss_cls : loss_bbox = 1 : 2.5
分类损失函数 VarifocalLoss¶
Varifocal Loss (VFL) 是 VarifocalNet: An IoU-aware Dense Object Detector 中的损失函数。

VFL 是在 GFL 的基础上做的改进,GFL详情请看 GFL详解
在上述标签匹配策略中提到过选择样本应该优先考虑分类回归都友好的样本点,
这是由于目标检测包含的分类与回归两个子任务都是作用于同一个物体。
与 GFL 思想相同,都是将 预测框与 GT 的 IoU 软化作为分类的标签,使得分类分数关联回归质量,
使其在后处理 NMS 阶段有分类回归一致性很强的分值排序策略,以达到选取优秀预测框的目的。
Varifocal Loss 原本的公式:
其中 \(q\) 是预测 bboxes 与 GT 的 IoU,使用软标签的形式作为分类的标签。
\(p\in[0,1]\) 表示分类分数。
对于负样本,即当 \(q = 0\) 时,标准交叉熵部分为 \(-\log(p)\),负样本权重使用 \(\alpha p^\gamma\) 作为
focal weight使样本聚焦与困难样本上,这与Focal Loss基本一致。对于正样本,即当 \(q > 0\) 时,首先计算标准二值交叉熵部分 \(-(qlog(p) +(1-q)log(1-p))\), 但是针对正样本的权重设置,
Varifocal Loss中并没有采用类似 \(\alpha p^\gamma\)的方式降权, 而是认为在网络的学习过程中正样本相对于负样本的学习信号来说更为重要,所以使用了分类的标签 \(q\), 即IoU作为focal weight, 使得聚焦到具有高质量的样本上。
但是 YOLOv6 中的 Varifocal Loss 公式采用 TOOD 中的 Task ALignment Learning (TAL),
将预测的 IoU 根据之前标签匹配策略中的分类对齐度 alignment_metrics 进行了归一化,
得到归一化 \(\hat{t}\)。
具体实现方式为:
对于每一个 Gt,找到所有样本中与 Gt 最大的 IoU,具有最大 alignment_metrics 的样本位置的 \(\hat{t} = max(Iou)\)
最终 YOLOv6 分类损失损失函数为:
MMDetection 实现源码的核心部分:
def varifocal_loss(pred, target, alpha=0.75, gamma=2.0, iou_weighted=True):
"""
pred (torch.Tensor): 预测的分类分数,形状为 (B,N,C) , N 表示 anchor 数量, C 表示类别数
target (torch.Tensor): 经过对齐度归一化后的 IoU 分数,形状为 (B,N,C),数值范围为 0~1
alpha (float, optional): 调节正负样本之间的平衡因子,默认 0.75.
gamma (float, optional): 负样本 focal 权重因子, 默认 2.0.
iou_weighted (bool, optional): 正样本是否用 IoU 加权
"""
pred_sigmoid = pred.sigmoid()
target = target.type_as(pred)
if iou_weighted:
# 计算权重,正样本(target > 0)中权重为 target,
# 负样本权重为 alpha*pred_simogid^2
focal_weight = target * (target > 0.0).float() + \
alpha * (pred_sigmoid - target).abs().pow(gamma) * \
(target <= 0.0).float()
else:
focal_weight = (target > 0.0).float() + \
alpha * (pred_sigmoid - target).abs().pow(gamma) * \
(target <= 0.0).float()
# 计算二值交叉熵后乘以权重
loss = F.binary_cross_entropy_with_logits(
pred, target, reduction='none') * focal_weight
loss = weight_reduce_loss(loss, weight, reduction, avg_factor)
return loss
回归损失函数 GIoU Loss / SIoU Loss¶
在 YOLOv6 中,针对不同大小的模型采用了不同的回归损失函数,其中 l/m/s使用的是 GIoULoss, t/n 用的是 SIoULoss。
其中 GIoULoss 详情请看 GIoU详解。
SIou Loss¶
SIoU 损失函数是 SIoU Loss: More Powerful Learning for Bounding Box Regression
中提出的度量预测框与 GT 的匹配度的指标,由于之前的GIoU, CIoU, DIoU 都没有考虑预测框向 GT
框回归的角度,然而角度也确实是回归中一个重要的影响因素,因此提出了全新的SIoU。
SIoU 损失主要由四个度量方面组成:
IoU成本
角度成本
距离成本
形状成本
如下图所示,角度成本 就是指图中预测框 \(B\) 向 \(B^{GT}\) 的回归过程中,
尽可能去使得优化过程中的不确定性因素减少,比如现将图中的角度 \(\alpha\) 或者 \(\beta\)
变为 0 ,再去沿着 x 轴或者 y 轴去回归边界。

MMYOLO 实现源码的核心部分:
def bbox_overlaps(bboxes1, bboxes2, mode='siou', is_aligned=False, eps=1e-6):
# 两个box的顶点x1,y1,x2,y2
bbox1_x1, bbox1_y1 = pred[:, 0], pred[:, 1]
bbox1_x2, bbox1_y2 = pred[:, 2], pred[:, 3]
bbox2_x1, bbox2_y1 = target[:, 0], target[:, 1]
bbox2_x2, bbox2_y2 = target[:, 2], target[:, 3]
# 交集
overlap = (torch.min(bbox1_x2, bbox2_x2) -
torch.max(bbox1_x1, bbox2_x1)).clamp(0) * \
(torch.min(bbox1_y2, bbox2_y2) -
torch.max(bbox1_y1, bbox2_y1)).clamp(0)
# 并集
w1, h1 = bbox1_x2 - bbox1_x1, bbox1_y2 - bbox1_y1
w2, h2 = bbox2_x2 - bbox2_x1, bbox2_y2 - bbox2_y1
union = (w1 * h1) + (w2 * h2) - overlap + eps
# IoU = 交集/并集
ious = overlap / union
# 最小外界矩的宽高
enclose_x1y1 = torch.min(pred[:, :2], target[:, :2])
enclose_x2y2 = torch.max(pred[:, 2:], target[:, 2:])
enclose_wh = (enclose_x2y2 - enclose_x1y1).clamp(min=0)
enclose_w = enclose_wh[:, 0] # enclose_w
enclose_h = enclose_wh[:, 1] # enclose_h
elif iou_mode == 'siou':
# 1.计算 σ (两个box中心点距离):
# sigma_cw,sigma_ch:上图中cw,ch
sigma_cw = (bbox2_x1 + bbox2_x2) / 2 - (bbox1_x1 + bbox1_x2) / 2 + eps
sigma_ch = (bbox2_y1 + bbox2_y2) / 2 - (bbox1_y1 + bbox1_y2) / 2 + eps
sigma = torch.pow(sigma_cw**2 + sigma_ch**2, 0.5)
# 2. 在 α 和 β 中选择一个小的角度(小于π/4)去优化
sin_alpha = torch.abs(sigma_ch) / sigma
sin_beta = torch.abs(sigma_cw) / sigma
sin_alpha = torch.where(sin_alpha <= math.sin(math.pi / 4), sin_alpha,
sin_beta)
# 角度损失 = 1 - 2 * ( sin^2 ( arcsin(x) - (π / 4) ) ) = cos(2α-π/2) = sin(2α)
# 这里就是角度损失,当 α=0 或者 α=90° 时损失为 0, 当 α=45° 损失为 1
angle_cost = torch.cos(torch.arcsin(sin_alpha) * 2 - math.pi / 2)
# 3.这里将角度损失与距离损失进行融合
# Distance cost = Σ_(t=x,y) (1 - e ^ (- γ ρ_t))
rho_x = (sigma_cw / enclose_w)**2 # ρ_x:x轴中心点距离距离损失
rho_y = (sigma_ch / enclose_h)**2 # ρ_y:y轴中心点距离距离损失
gamma = 2 - angle_cost # γ
# 当 α=0, angle_cost=0, gamma=2, dis_cost_x = 1 - e ^ (-2 p_x),因为 ρ_x>0, 主要优化距离
# 当 α=45°,angle_cost=1, gamma=1, dis_cost_x = 1 - e ^ (-1* p_x),因为 ρ_x<1, 主要优化角度
distance_cost = (1 - torch.exp(-1 * gamma * rho_x)) + (
1 - torch.exp(-1 * gamma * rho_y))
# 4.形状损失 就是两个box之间的宽高比
# Shape cost = Ω = Σ_(t=w,h) ( ( 1 - ( e ^ (-ω_t) ) ) ^ θ )
omiga_w = torch.abs(w1 - w2) / torch.max(w1, w2) # ω_w
omiga_h = torch.abs(h1 - h2) / torch.max(h1, h2) # ω_h
shape_cost = torch.pow(1 - torch.exp(-1 * omiga_w),
siou_theta) + torch.pow(
1 - torch.exp(-1 * omiga_h), siou_theta)
# 5.综合 IoU、角度、距离以及形状信息
# SIoU = IoU - ( (Distance Cost + Shape Cost) / 2 )
ious = ious - ((distance_cost + shape_cost) * 0.5)
return ious.clamp(min=-1.0, max=1.0)
@weighted_loss
def siou_loss(pred, target, eps=1e-7):
sious = bbox_overlaps(pred, target, mode='siou', is_aligned=True, eps=eps)
loss = 1 - sious
return loss
Object Loss¶
在 YOLOv6 中,由于额外的置信度预测头可能与 Aligned Head 有所冲突,经实验验证在不同大小的模型上也都有掉点,
所以最后选择弃用 Objectness 分支。
1.5 优化策略和训练过程¶
1.5.1 优化器分组¶
与 YOLOv5 一致,详情请看 YOLOv5 优化器分组
1.5.2 weight decay 参数自适应¶
与 YOLOv5 一致,详情请看 YOLOv5 weight decay 参数自适应
1.6 推理和后处理过程¶
YOLOv6 后处理过程和 YOLOv5 高度类似,实际上 YOLO 系列的后处理逻辑都是类似的。 详情请看 YOLOv5 推理和后处理过程
2 总结¶
本文对 YOLOv6 原理和在 MMYOLO 实现进行了详细解析,希望能帮助用户理解算法实现过程。同时请注意:由于 YOLOv6 本身也在不断更新,本开源库也会不断迭代,请及时阅读和同步最新版本。