训练和测试技巧¶
MMYOLO 中已经支持了大部分 YOLO 系列目标检测相关算法。不同算法可能涉及到一些实用技巧。本章节将基于所实现的目标检测算法,详细描述 MMYOLO 中已经支持的常用的训练和测试技巧。
训练技巧¶
提升检测性能¶
1 开启多尺度训练¶
在目标检测领域,多尺度训练是一个非常常用的技巧,但是在 YOLO 中大部分模型的训练输入都是单尺度的 640x640,原因有两个方面:
单尺度训练速度快。当训练 epoch 在 300 或者 500 的时候训练效率是用户非常关注的,多尺度训练会比较慢
训练 pipeline 中隐含了多尺度增强,等价于应用了多尺度训练,典型的如
Mosaic、RandomAffine和Resize等,故没有必要再次引入模型输入的多尺度训练
在 COCO 数据集上进行了简单实验,如果直接在 YOLOv5 的 DataLoader 输出后再次引入多尺度训练增强实际性能提升非常小,但是这不代表用户自定义数据集微调模式下没有明显增益。如果想在 MMYOLO 中对 YOLO 系列算法开启多尺度训练,可以参考 多尺度训练文档
2 使用 Mask 标注优化目标检测性能¶
在数据集标注完备例如同时存在边界框和实例分割标注但任务只需要其中部分标注情况下,可以借助完备的数据标注训练单一任务从而提升性能。在目标检测中同样可以借鉴实例分割标注来提升目标检测性能。 以下是 YOLOv8 额外引入实例分割标注优化目标检测结果。 性能增益如下所示:

从上述曲线图可以看出,不同尺度模型都有了不同程度性能提升。需要注意的是 Mask Refine 仅仅的是作用在数据增强阶段,对模型其他训练部分不需要任何改动,且不会影响训练速度。具体如下所示:
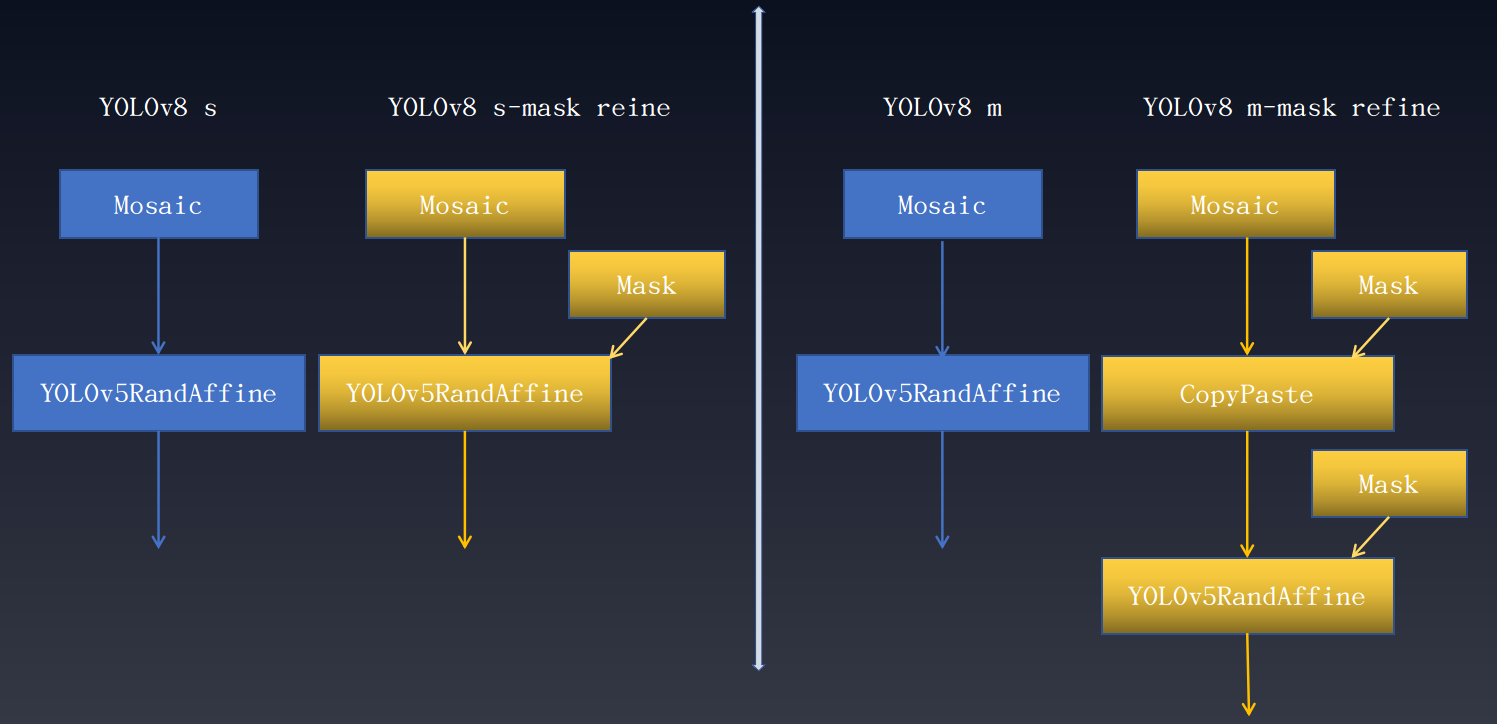
上述的 Mask 表示实例分割标注发挥关键作用的数据增强变换,将该技巧应用到其他 YOLO 系列中均有不同程度涨点。
3 训练后期关闭强增强提升检测性能¶
该策略是在 YOLOX 算法中第一次被提出可以极大的提升检测性能。 论文中指出虽然 Mosaic+MixUp 可以极大的提升目标检测性能,但是它生成的训练图片远远脱离自然图片的真实分布,并且 Mosaic 大量的裁剪操作会带来很多不准确的标注框,所以 YOLOX 提出在最后 15 个 epoch 关掉强增强,转而使用较弱的增强,从而为了让检测器避开不准确标注框的影响,在自然图片的数据分布下完成最终的收敛。
该策略已经被应用到了大部分 YOLO 算法中,以 YOLOv8 为例其数据增强 pipeline 如下所示:

不过在何时关闭强增强是一个超参,如果关闭太早则可能没有充分发挥 Mosaic 等强增强效果,如果关闭太晚则由于之前已经过拟合,此时再关闭则没有任何增益。 在 YOLOv8 实验中可以观察到该现象
| Backbone | Mask Refine | box AP | Epoch of best mAP |
|---|---|---|---|
| YOLOv8-n | No | 37.2 | 500 |
| YOLOv8-n | Yes | 37.4 (+0.2) | 499 |
| YOLOv8-s | No | 44.2 | 430 |
| YOLOv8-s | Yes | 45.1 (+0.9) | 460 |
| YOLOv8-m | No | 49.8 | 460 |
| YOLOv8-m | Yes | 50.6 (+0.8) | 480 |
| YOLOv8-l | No | 52.1 | 460 |
| YOLOv8-l | Yes | 53.0 (+0.9) | 491 |
| YOLOv8-x | No | 52.7 | 450 |
| YOLOv8-x | Yes | 54.0 (+1.3) | 460 |
从上表可以看出:
大模型在 COCO 数据集训练 500 epoch 会过拟合,在过拟合情况下再关闭 Mosaic 等强增强效果没有效果
使用 Mask 标注可以缓解过拟合,并且提升性能
4 加入纯背景图片抑制误报率¶
对于非开放世界数据集目标检测而言,训练和测试都是在固定类别上进行,一旦应用到没有训练过的类别图片上有可能会产生误报,一个常见的缓解策略是加入一定比例的纯背景图片。 在大部分 YOLO 系列中都是默认开启了加入纯背景图片抑制误报率功能,用户只需要设置 train_dataloader.dataset.filter_cfg.filter_empty_gt 为 False 即可,表示将纯背景图片不过滤掉加入训练。
5 试试 AdamW 也许效果显著¶
YOLOv5,YOLOv6,YOLOv7 和 YOLOv8 等都是采用了 SGD 优化器,该参数器对参数的设置比较严格,而 AdamW 则正好相反,其对学习率设置等没有那么敏感。因此如果用户在自定义数据集微调可以尝试选择 AdamW 优化器。我们在 YOLOX 中进行了简单尝试,发现在 tiny、s 和 m 尺度模型上将其优化器替换为 AdamW 均有一定程度涨点。
| Backbone | Size | Batch Size | RTMDet-Hyp | Box AP |
|---|---|---|---|---|
| YOLOX-tiny | 416 | 8xb8 | No | 32.7 |
| YOLOX-tiny | 416 | 8xb32 | Yes | 34.3 (+1.6) |
| YOLOX-s | 640 | 8xb8 | No | 40.7 |
| YOLOX-s | 640 | 8xb32 | Yes | 41.9 (+1.2) |
| YOLOX-m | 640 | 8xb8 | No | 46.9 |
| YOLOX-m | 640 | 8xb32 | Yes | 47.5 (+0.6) |
6 考虑 ignore 场景避免不确定性标注¶
以 CrowdHuman 为例,其是一个拥挤行人检测数据集,下面是一张典型图片:

图片来自 detectron2 issue。黄色打叉的区域表示 iscrowd 标注。原因有两个方面:
这个区域不是真的人,例如海报上的人
该区域过于拥挤,很难标注
在该场景下,你不能简单的将这类标注删掉,因为你一旦删掉就表示当做背景区域来训练了,但是其和背景是不一样的,首先海报上的人和真人很像,并且拥挤区域确实有人只是不好标注。如果你简单的将其当做背景训练,那么会造成漏报。最合适的做法应该是把拥挤区域当做忽略区域即该区域的任何输出都直接忽略,不计算任何 Loss,不强迫模型拟合。
MMYOLO 在 YOLOv5 上简单快速的验证了 iscrowd 标注的作用,性能如下所示:
| Backbone | ignore_iof_thr | box AP50(CrowDHuman Metric) | MR | JI |
|---|---|---|---|---|
| YOLOv5-s | -1 | 85.79 | 48.7 | 75.33 |
| YOLOv5-s | 0.5 | 86.17 | 48.8 | 75.87 |
ignore_iof_thr为 -1 表示不考虑忽略标签,可以看出性能有一定程度的提升,具体见 CrowdHuman 结果。 如果你的自定义数据集上也有上述情况,则建议你考虑 ignore 场景避免不确定性标注。
7 使用知识蒸馏¶
知识蒸馏是一个被广泛使用的技巧,可以将大模型性能转移到小模型上从而提升小模型检测性能。 目前 MMYOLO 和 MMRazor 已支持了该功能,并在 RTMDet 上进行了初步验证。
| Model | box AP |
|---|---|
| RTMDet-tiny | 41.0 |
| RTMDet-tiny * | 41.8 (+0.8) |
| RTMDet-s | 44.6 |
| RTMDet-s * | 45.7 (+1.1) |
| RTMDet-m | 49.3 |
| RTMDet-m * | 50.2 (+0.9) |
| RTMDet-l | 51.4 |
| RTMDet-l * | 52.3 (+0.9) |
星号即为采用了大模型蒸馏的结果,详情见 Distill RTMDet。
8 更大的模型用更强的增强参数¶
如果你基于默认配置修改了模型或者替换了骨干网络,那么建议你基于此刻模型大小来缩放数据增强参数。 一般来说更大的模型需要使用更强的增强参数,否则可能无法发挥大模型的效果,反之如果小模型应用了较强的增强则可能会欠拟合。 以 RTMDet 为例,我们可以观察其不同模型大小的数据增强参数

其中 random_resize_ratio_range 表示 RandomResize 的随机缩放范围,mosaic_max_cached_images/mixup_max_cached_images表示 Mosaic/MixUp 增强时候缓存的图片个数,可以用于调整增强的强度。 YOLO 系列模型都是遵循同一套参数设置原则。
加快训练速度¶
1 单尺度训练开启 cudnn_benchmark¶
YOLO 系列算法中大部分网络输入图片大小都是固定的即单尺度,此时可以开启 cudnn_benchmark 来加快训练速度。该参数主要针对 PyTorch 的 cuDNN 底层库进行设置, 设置这个标志可以让内置的 cuDNN 自动寻找最适合当前配置的高效算法来优化运行效率。如果是多尺度模式开启该标志则会不断的寻找最优算法,反而会拖慢训练速度。
在 MMYOLO 中开启 cudnn_benchmark,只需要在配置中设置 env_cfg = dict(cudnn_benchmark=True)
2 使用带缓存的 Mosaic 和 MixUp¶
如果你的数据增强中应用了 Mosaic 和 MixUp,并且经过排查训练瓶颈来自图片的随机读取,那么建议将常规的 Mosaic 和 MixUp 替换为 RTMDet 中提出的带缓存的版本。
| Data Aug | Use cache | ms/100 imgs |
|---|---|---|
| Mosaic | No | 87.1 |
| Mosaic | Yes | 24.0 |
| MixUp | No | 19.3 |
| MixUp | Yes | 12.4 |
Mosaic 和 MixUp 涉及到多张图片的混合,它们的耗时会是普通数据增强的 K 倍(K 为混入图片的数量)。 如在 YOLOv5 中每次做 Mosaic 时, 4 张图片的信息都需要从硬盘中重新加载。 而带缓存的 Mosaic 和 MixUp 只需要重新载入当前的一张图片,其余参与混合增强的图片则从缓存队列中获取,通过牺牲一定内存空间的方式大幅提升了效率。
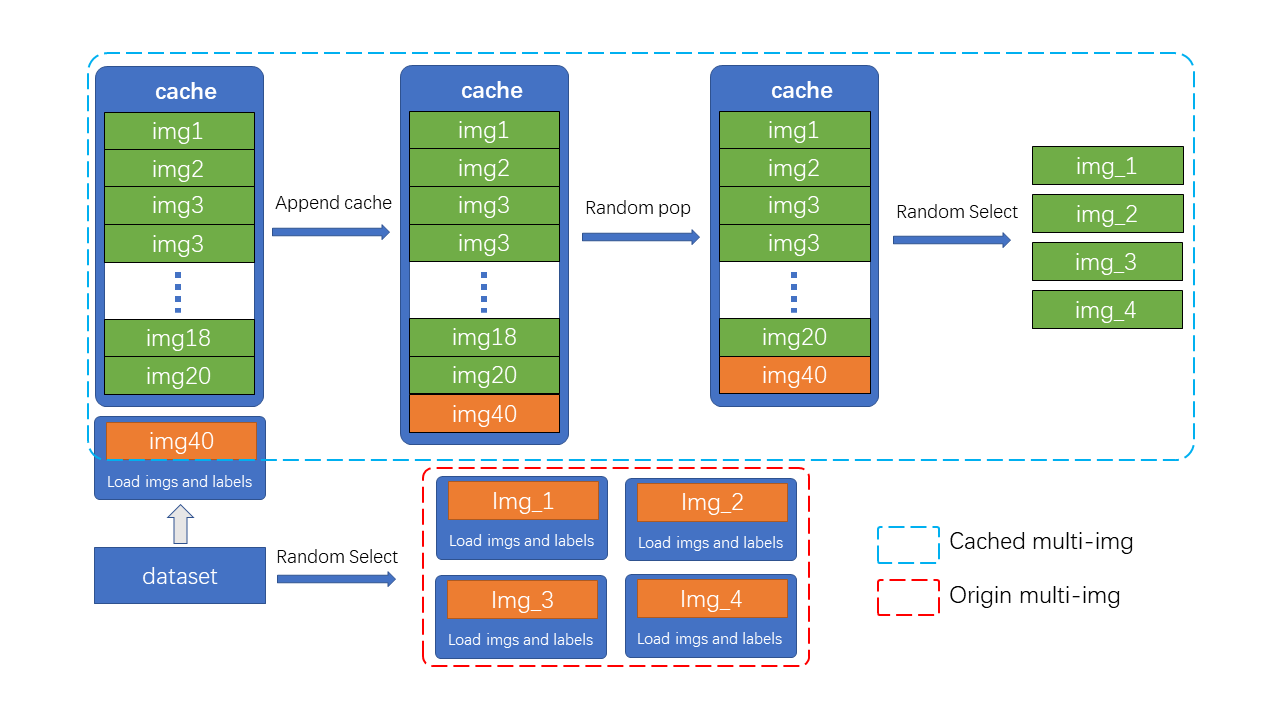
如图所示,cache 队列中预先储存了 N 张已加载的图像与标签数据,每一个训练 step 中只需加载一张新的图片及其标签数据并更新到 cache 队列中(cache 队列中的图像可重复,如图中出现两次 img3),同时如果 cache 队列长度超过预设长度,则随机 pop 一张图,当需要进行混合数据增强时,只需要从 cache 中随机选择需要的图像进行拼接等处理,而不需要全部从硬盘中加载,节省了图像加载的时间。
减少超参¶
YOLOv5 中通过实践提供了一些减少超参数的方法,下面详细说明。
1 Loss 权重自适应,少 1 个超参¶
一般来说,对于不同的任务或者不同的类别,可能需要针对性的设置超参,而这通常比较难。YOLOv5 中根据实践提出了一些根据类别数和检测输出层个数来自适应缩放 Loss 权重的方法,如下所示:
# scaled based on number of detection layers
loss_cls=dict(
type='mmdet.CrossEntropyLoss',
use_sigmoid=True,
reduction='mean',
loss_weight=loss_cls_weight *
(num_classes / 80 * 3 / num_det_layers)),
loss_bbox=dict(
type='IoULoss',
iou_mode='ciou',
bbox_format='xywh',
eps=1e-7,
reduction='mean',
loss_weight=loss_bbox_weight * (3 / num_det_layer
return_iou=True),
loss_obj=dict(
type='mmdet.CrossEntropyLoss',
use_sigmoid=True,
reduction='mean',
loss_weight=loss_obj_weight *
((img_scale[0] / 640)**2 * 3 / num_det_layers)),
loss_cls 可以根据自定义类别数和检测层数对 loss_weight 进行自适应缩放,loss_bbox 可以根据检测层数进行自适应计算,而 loss_obj 可以根据输入图片大小和检测层数进行自适应缩放。这种策略可以让用户不用去设置 Loss 权重超参。
需要说明的是:这个只是经验规则,并不是说是最佳设置组合,只是作为一个参考。
2 Weight Decay 和 Loss 输出值基于 Batch Size 自适应,少 2 个超参¶
一般来说,在不同的 Batch Size 上进行训练,需要遵循学习率自动缩放规则。但是在各个数据集上验证表明 YOLOv5 实际上在改变 Batch Size 时候不缩放学习率也可以取得不错的效果,甚至有时候你缩放了效果还更差。原因就在于代码中存在 Weight Decay 和 Loss 输出值基于 Batch Size 自适应的技巧。在 YOLOv5 中会基于当前训练的总 Batch Size 来缩放 Weight Decay 和 Loss 输出值。对应代码为:
# https://github.com/open-mmlab/mmyolo/blob/dev/mmyolo/engine/optimizers/yolov5_optim_constructor.py#L86
if 'batch_size_per_gpu' in optimizer_cfg:
batch_size_per_gpu = optimizer_cfg.pop('batch_size_per_gpu')
# No scaling if total_batch_size is less than
# base_total_batch_size, otherwise linear scaling.
total_batch_size = get_world_size() * batch_size_per_gpu
accumulate = max(
round(self.base_total_batch_size / total_batch_size), 1)
scale_factor = total_batch_size * \
accumulate / self.base_total_batch_size
if scale_factor != 1:
weight_decay *= scale_factor
print_log(f'Scaled weight_decay to {weight_decay}', 'current')
# https://github.com/open-mmlab/mmyolo/blob/dev/mmyolo/models/dense_heads/yolov5_head.py#L635
_, world_size = get_dist_info()
return dict(
loss_cls=loss_cls * batch_size * world_size,
loss_obj=loss_obj * batch_size * world_size,
loss_bbox=loss_box * batch_size * world_size)
在不同的 Batch Size 下 Loss 的权重是不一样大的,Batch Size 越大,Loss 就越大,梯度就越大,我个人猜测这可以等价于 Batch Size 增大时候,学习率线性增加的场合。 实际上从 YOLOv5 的 YOLOv5 Study: mAP vs Batch-Size 中可以发现确实是希望用户在修改 Batch Size 时不需要修改其他参数也可以相近的性能。上述两个策略是一个非常不错的训练技巧。
测试技巧¶
推理速度和测试精度的平衡¶
在模型性能测试时候,我们一般是要求 mAP 越高越好,但是在实际应用或者推理时候我们希望在保证低误报率和漏报率情况下模型推理越快越好,或者说测试只关注 mAP 而忽略了后处理和评估速度,而实际落地应用时候会追求速度和精度的平衡。 在 YOLO 系列中可以通过控制某些参数实现速度和精度平衡,下面以 YOLOv5 为例对其进行详细描述。
1 推理时避免一个检测框输出多个类别¶
YOLOv5 在训练分类分支时候采用的是 BCE Loss 即 use_sigmoid=True。假设物体类别数是 4,那么分类分支输出的类别数是 4 而不是 5,并且由于使用的是 sigmoid 而非 softmax 预测模式,很可能在某个位置预测出多个满足过滤阈值的检测框,也就是会出现一个预测 bbox 对应多个预测 label 的情况。如下图所示

一般在计算 mAP 时候过滤阈值为 0.001,由于 sigmoid 非竞争性预测模式会导致一个框对应多个 label。这种计算方式可以提高 mAP 计算时候的召回率,但是实际落地应用会不方便。
一个常用的办法就是提高过滤阈值,但是如果你不需要出现较多漏报,此时推荐你修改 multi_label 参数为 False,其位于配置的 mode.test_cfg.multi_label 中,默认值是 True 表示允许一个检测框对应多个 label。
2 简化 test pipeline¶
注意到 YOLOv5 的 test pipeline 为如下:
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
dict(
type='LetterResize',
scale=img_scale,
allow_scale_up=False,
pad_val=dict(img=114)),
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor', 'pad_param'))
]
其使用了两个不同功能的 Resize,目的依然是提高评估时候的 mAP 值。在实际落地应用时候你可以简化该 pipeline,如下所示:
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='LetterResize',
scale=_base_.img_scale,
allow_scale_up=True,
use_mini_pad=True),
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor', 'pad_param'))
]
实际上 YOLOv5 算法在实际应用时候是采用简化的 pipeline,并将 multi_label 设为 False, score_thr 提高为 0.25, iou_threshold 降低为 0.45。 在 YOLOv5 配置中我们提供了一套 detect 落地时候的配置参数,具体见 yolov5_s-v61_syncbn-detect_8xb16-300e_coco.py。
3 Batch Shape 策略加快测试速度¶
Batch Shape 是 YOLOv5 中提出的可以加快推理的一个测试技巧,其思路是不再强制要求整个测试过程图片都是 640x640,而是可以变尺度测试,只需要保证当前 batch 内的 shape 是一样的就行。这种方式可以减少额外的图片像素填充,从而实现加速推理过程。
Batch Shape 的具体实现可以参考 链接。MMYOLO 中几乎所有算法在测试时候都是默认开启了 Batch Shape 策略。 如果用户想关闭该功能,可以设置 val_dataloader.dataset.batch_shapes_cfg=None。
在实际落地场景下,因为动态 shape 没有固定 shape 快且高效,所以一般会不采用这个策略。