YOLOv5 部署全流程说明¶
请先参考 部署必备指南 了解部署配置文件等相关信息。
模型训练和测试¶
模型训练和测试请参考 YOLOv5 从入门到部署全流程 。
准备 MMDeploy 运行环境¶
安装 MMDeploy 请参考 源码手动安装 ,选择您所使用的平台编译 MMDeploy 和自定义算子。
注意! 如果环境安装有问题,可以查看 MMDeploy FAQ 或者在 issuse 中提出您的问题。
准备模型配置文件¶
本例将以基于 coco 数据集预训练的 YOLOv5 配置和权重进行部署的全流程讲解,包括静态/动态输入模型导出和推理,TensorRT / ONNXRuntime 两种后端部署和测试。
静态输入配置¶
(1) 模型配置文件¶
当您需要部署静态输入模型时,您应该确保模型的输入尺寸是固定的,比如在测试流程或测试数据集加载时输入尺寸为 640x640。
您可以查看 yolov5_s-static.py 中测试流程或测试数据集加载部分,如下所示:
_base_ = '../../yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
test_pipeline = [
dict(type='LoadImageFromFile', backend_args=_base_.backend_args),
dict(
type='LetterResize',
scale=_base_.img_scale,
allow_scale_up=False,
use_mini_pad=False,
),
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor', 'pad_param'))
]
test_dataloader = dict(
dataset=dict(pipeline=test_pipeline, batch_shapes_cfg=None))
由于 yolov5 在测试时会开启 allow_scale_up 和 use_mini_pad 改变输入图像的尺寸来取得更高的精度,但是会给部署静态输入模型造成输入尺寸不匹配的问题。
该配置相比与原始配置文件进行了如下修改:
关闭
test_pipline中改变尺寸相关的配置,如LetterResize中allow_scale_up=False和use_mini_pad=False。关闭
test_dataloader中batch shapes策略,即batch_shapes_cfg=None。
(2) 部署配置文件¶
当您部署在 ONNXRuntime 时,您可以查看 detection_onnxruntime_static.py ,如下所示:
_base_ = ['./base_static.py']
codebase_config = dict(
type='mmyolo',
task='ObjectDetection',
model_type='end2end',
post_processing=dict(
score_threshold=0.05,
confidence_threshold=0.005,
iou_threshold=0.5,
max_output_boxes_per_class=200,
pre_top_k=5000,
keep_top_k=100,
background_label_id=-1),
module=['mmyolo.deploy'])
backend_config = dict(type='onnxruntime')
默认配置中的 post_processing 后处理参数是当前模型与 pytorch 模型精度对齐的配置,若您需要修改相关参数,可以参考 部署必备指南 的详细介绍。
当您部署在 TensorRT 时,您可以查看 detection_tensorrt_static-640x640.py ,如下所示:
_base_ = ['./base_static.py']
onnx_config = dict(input_shape=(640, 640))
backend_config = dict(
type='tensorrt',
common_config=dict(fp16_mode=False, max_workspace_size=1 << 30),
model_inputs=[
dict(
input_shapes=dict(
input=dict(
min_shape=[1, 3, 640, 640],
opt_shape=[1, 3, 640, 640],
max_shape=[1, 3, 640, 640])))
])
use_efficientnms = False
本例使用了默认的输入尺寸 input_shape=(640, 640) ,构建网络以 fp32 模式即 fp16_mode=False,并且默认构建 TensorRT 构建引擎所使用的显存 max_workspace_size=1 << 30 即最大为 1GB 显存。
动态输入配置¶
(1) 模型配置文件¶
当您需要部署动态输入模型时,模型的输入可以为任意尺寸(TensorRT 会限制最小和最大输入尺寸),因此使用默认的 yolov5_s-v61_syncbn_8xb16-300e_coco.py 模型配置文件即可,其中数据处理和数据集加载器部分如下所示:
batch_shapes_cfg = dict(
type='BatchShapePolicy',
batch_size=val_batch_size_per_gpu,
img_size=img_scale[0],
size_divisor=32,
extra_pad_ratio=0.5)
test_pipeline = [
dict(type='LoadImageFromFile', backend_args=_base_.backend_args),
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
dict(
type='LetterResize',
scale=img_scale,
allow_scale_up=False,
pad_val=dict(img=114)),
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor', 'pad_param'))
]
val_dataloader = dict(
batch_size=val_batch_size_per_gpu,
num_workers=val_num_workers,
persistent_workers=persistent_workers,
pin_memory=True,
drop_last=False,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=dict(
type=dataset_type,
data_root=data_root,
test_mode=True,
data_prefix=dict(img='val2017/'),
ann_file='annotations/instances_val2017.json',
pipeline=test_pipeline,
batch_shapes_cfg=batch_shapes_cfg))
其中 LetterResize 类初始化传入了 allow_scale_up=False 控制输入的小图像是否上采样,同时默认 use_mini_pad=False 关闭了图片最小填充策略,val_dataloader['dataset']中传入了 batch_shapes_cfg=batch_shapes_cfg,即按照 batch 内的输入尺寸进行最小填充。上述策略会改变输入图像的尺寸,因此动态输入模型在测试时会按照上述数据集加载器动态输入。
(2) 部署配置文件¶
当您部署在 ONNXRuntime 时,您可以查看 detection_onnxruntime_dynamic.py ,如下所示:
_base_ = ['./base_dynamic.py']
codebase_config = dict(
type='mmyolo',
task='ObjectDetection',
model_type='end2end',
post_processing=dict(
score_threshold=0.05,
confidence_threshold=0.005,
iou_threshold=0.5,
max_output_boxes_per_class=200,
pre_top_k=5000,
keep_top_k=100,
background_label_id=-1),
module=['mmyolo.deploy'])
backend_config = dict(type='onnxruntime')
与静态输入配置仅有 _base_ = ['./base_dynamic.py'] 不同,动态输入会额外继承 dynamic_axes 属性。其他配置与静态输入配置相同。
当您部署在 TensorRT 时,您可以查看 detection_tensorrt_dynamic-192x192-960x960.py ,如下所示:
_base_ = ['./base_dynamic.py']
backend_config = dict(
type='tensorrt',
common_config=dict(fp16_mode=False, max_workspace_size=1 << 30),
model_inputs=[
dict(
input_shapes=dict(
input=dict(
min_shape=[1, 3, 192, 192],
opt_shape=[1, 3, 640, 640],
max_shape=[1, 3, 960, 960])))
])
use_efficientnms = False
本例构建网络以 fp32 模式即 fp16_mode=False,构建 TensorRT 构建引擎所使用的显存 max_workspace_size=1 << 30 即最大为 1GB 显存。
同时默认配置 min_shape=[1, 3, 192, 192],opt_shape=[1, 3, 640, 640] ,max_shape=[1, 3, 960, 960] ,意为该模型所能接受的输入尺寸最小为 192x192 ,最大为 960x960,最常见尺寸为 640x640。
当您部署自己的模型时,需要根据您的输入图像尺寸进行调整。
模型转换¶
本教程所使用的 MMDeploy 根目录为 /home/openmmlab/dev/mmdeploy,请注意修改为您的 MMDeploy 目录。
预训练权重下载于 yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth ,保存在本地的 /home/openmmlab/dev/mmdeploy/yolov5s.pth。
wget https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth -O /home/openmmlab/dev/mmdeploy/yolov5s.pth
命令行执行以下命令配置相关路径:
export MMDEPLOY_DIR=/home/openmmlab/dev/mmdeploy
export PATH_TO_CHECKPOINTS=/home/openmmlab/dev/mmdeploy/yolov5s.pth
YOLOv5 静态输入模型导出¶
ONNXRuntime¶
python3 ${MMDEPLOY_DIR}/tools/deploy.py \
configs/deploy/detection_onnxruntime_static.py \
configs/deploy/model/yolov5_s-static.py \
${PATH_TO_CHECKPOINTS} \
demo/demo.jpg \
--work-dir work_dir \
--show \
--device cpu
TensorRT¶
python3 ${MMDEPLOY_DIR}/tools/deploy.py \
configs/deploy/detection_tensorrt_static-640x640.py \
configs/deploy/model/yolov5_s-static.py \
${PATH_TO_CHECKPOINTS} \
demo/demo.jpg \
--work-dir work_dir \
--show \
--device cuda:0
YOLOv5 动态输入模型导出¶
ONNXRuntime¶
python3 ${MMDEPLOY_DIR}/tools/deploy.py \
configs/deploy/detection_onnxruntime_dynamic.py \
configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py \
${PATH_TO_CHECKPOINTS} \
demo/demo.jpg \
--work-dir work_dir \
--show \
--device cpu
--dump-info
TensorRT¶
python3 ${MMDEPLOY_DIR}/tools/deploy.py \
configs/deploy/detection_tensorrt_dynamic-192x192-960x960.py \
configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py \
${PATH_TO_CHECKPOINTS} \
demo/demo.jpg \
--work-dir work_dir \
--show \
--device cuda:0
--dump-info
当您使用上述命令转换模型时,您将会在 work_dir 文件夹下发现以下文件:
或者
在导出 onnxruntime模型后,您将得到图1的六个文件,其中 end2end.onnx 表示导出的onnxruntime模型,xxx.json 表示 MMDeploy SDK 推理所需要的 meta 信息。
在导出 TensorRT模型后,您将得到图2的七个文件,其中 end2end.onnx 表示导出的中间模型,MMDeploy利用该模型自动继续转换获得 end2end.engine 模型用于 TensorRT 部署,xxx.json 表示 MMDeploy SDK 推理所需要的 meta 信息。
模型评测¶
当您转换模型成功后,可以使用 ${MMDEPLOY_DIR}/tools/test.py 工具对转换后的模型进行评测。下面是对 ONNXRuntime 和 TensorRT 静态模型的评测,动态模型评测修改传入模型配置即可。
ONNXRuntime¶
python3 ${MMDEPLOY_DIR}/tools/test.py \
configs/deploy/detection_onnxruntime_static.py \
configs/deploy/model/yolov5_s-static.py \
--model work_dir/end2end.onnx \
--device cpu \
--work-dir work_dir
执行完成您将看到命令行输出检测结果指标如下:
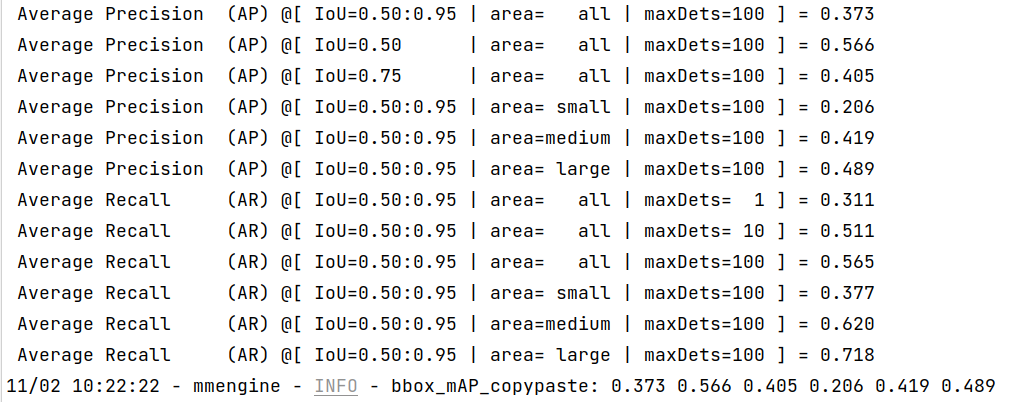
TensorRT¶
注意: TensorRT 需要执行设备是 cuda
python3 ${MMDEPLOY_DIR}/tools/test.py \
configs/deploy/detection_tensorrt_static-640x640.py \
configs/deploy/model/yolov5_s-static.py \
--model work_dir/end2end.engine \
--device cuda:0 \
--work-dir work_dir
执行完成您将看到命令行输出检测结果指标如下:
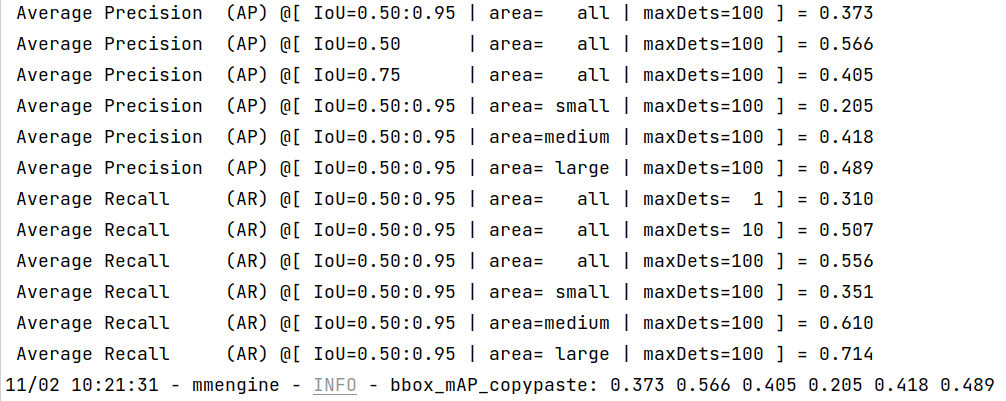
未来我们将会支持模型测速等更加实用的脚本
使用 Docker 部署测试¶
MMYOLO 提供了一个 Dockerfile 用于构建镜像。请确保您的 docker 版本大于等于 19.03。
温馨提示;国内用户建议取消掉 Dockerfile 里面 Optional 后两行的注释,可以获得火箭一般的下载提速:
# (Optional)
RUN sed -i 's/http:\/\/archive.ubuntu.com\/ubuntu\//http:\/\/mirrors.aliyun.com\/ubuntu\//g' /etc/apt/sources.list && \
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
构建命令:
# build an image with PyTorch 1.12, CUDA 11.6, TensorRT 8.2.4 ONNXRuntime 1.8.1
docker build -f docker/Dockerfile_deployment -t mmyolo:v1 .
用以下命令运行 Docker 镜像:
export DATA_DIR=/path/to/your/dataset
docker run --gpus all --shm-size=8g -it --name mmyolo -v ${DATA_DIR}:/openmmlab/mmyolo/data/coco mmyolo:v1
DATA_DIR 是 COCO 数据的路径。
复制以下脚本到 docker 容器 /openmmlab/mmyolo/script.sh:
#!/bin/bash
wget -q https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth \
-O yolov5s.pth
export MMDEPLOY_DIR=/openmmlab/mmdeploy
export PATH_TO_CHECKPOINTS=/openmmlab/mmyolo/yolov5s.pth
python3 ${MMDEPLOY_DIR}/tools/deploy.py \
configs/deploy/detection_tensorrt_static-640x640.py \
configs/deploy/model/yolov5_s-static.py \
${PATH_TO_CHECKPOINTS} \
demo/demo.jpg \
--work-dir work_dir_trt \
--device cuda:0
python3 ${MMDEPLOY_DIR}/tools/test.py \
configs/deploy/detection_tensorrt_static-640x640.py \
configs/deploy/model/yolov5_s-static.py \
--model work_dir_trt/end2end.engine \
--device cuda:0 \
--work-dir work_dir_trt
python3 ${MMDEPLOY_DIR}/tools/deploy.py \
configs/deploy/detection_onnxruntime_static.py \
configs/deploy/model/yolov5_s-static.py \
${PATH_TO_CHECKPOINTS} \
demo/demo.jpg \
--work-dir work_dir_ort \
--device cpu
python3 ${MMDEPLOY_DIR}/tools/test.py \
configs/deploy/detection_onnxruntime_static.py \
configs/deploy/model/yolov5_s-static.py \
--model work_dir_ort/end2end.onnx \
--device cpu \
--work-dir work_dir_ort
在 /openmmlab/mmyolo 下运行:
sh script.sh
脚本会自动下载 MMYOLO 的 YOLOv5 预训练权重并使用 MMDeploy 进行模型转换和测试。您将会看到以下输出:
TensorRT:
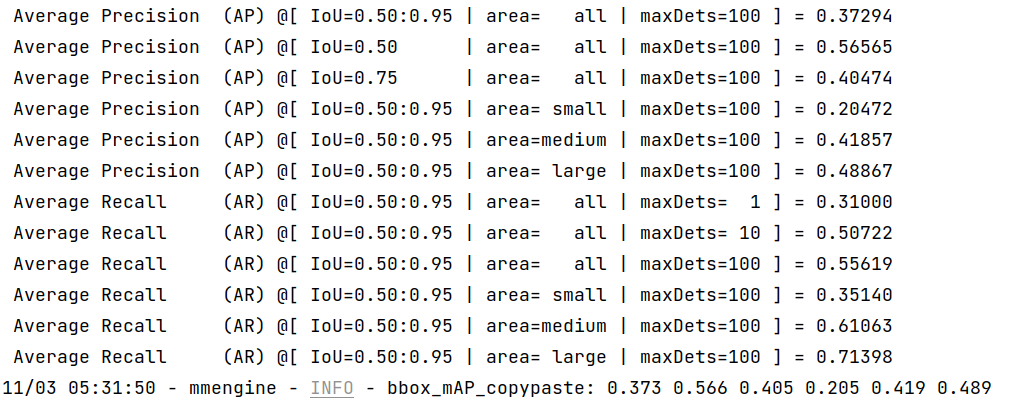
ONNXRuntime:
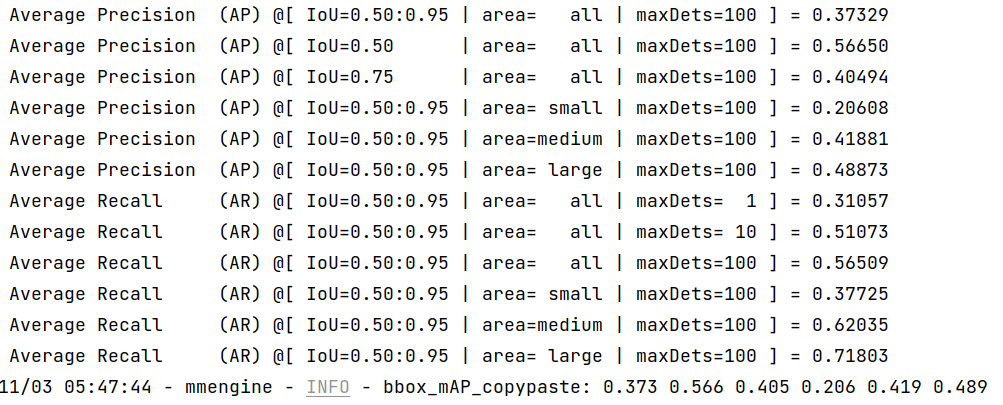
可以看到,经过 MMDeploy 部署的模型与 MMYOLO-YOLOv5 的 mAP-37.7 差距在 1% 以内。
如果您需要测试您的模型推理速度,可以使用以下命令:
TensorRT
python3 ${MMDEPLOY_DIR}/tools/profiler.py \
configs/deploy/detection_tensorrt_static-640x640.py \
configs/deploy/model/yolov5_s-static.py \
data/coco/val2017 \
--model work_dir_trt/end2end.engine \
--device cuda:0
ONNXRuntime
python3 ${MMDEPLOY_DIR}/tools/profiler.py \
configs/deploy/detection_onnxruntime_static.py \
configs/deploy/model/yolov5_s-static.py \
data/coco/val2017 \
--model work_dir_ort/end2end.onnx \
--device cpu
模型推理¶
后端模型推理¶
ONNXRuntime¶
以上述模型转换后的 end2end.onnx 为例,您可以使用如下代码进行推理:
from mmdeploy.apis.utils import build_task_processor
from mmdeploy.utils import get_input_shape, load_config
import torch
deploy_cfg = './configs/deploy/detection_onnxruntime_dynamic.py'
model_cfg = '../mmyolo/configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
device = 'cpu'
backend_model = ['./work_dir/end2end.onnx']
image = '../mmyolo/demo/demo.jpg'
# read deploy_cfg and model_cfg
deploy_cfg, model_cfg = load_config(deploy_cfg, model_cfg)
# build task and backend model
task_processor = build_task_processor(model_cfg, deploy_cfg, device)
model = task_processor.build_backend_model(backend_model)
# process input image
input_shape = get_input_shape(deploy_cfg)
model_inputs, _ = task_processor.create_input(image, input_shape)
# do model inference
with torch.no_grad():
result = model.test_step(model_inputs)
# visualize results
task_processor.visualize(
image=image,
model=model,
result=result[0],
window_name='visualize',
output_file='work_dir/output_detection.png')
TensorRT¶
以上述模型转换后的 end2end.engine 为例,您可以使用如下代码进行推理:
from mmdeploy.apis.utils import build_task_processor
from mmdeploy.utils import get_input_shape, load_config
import torch
deploy_cfg = './configs/deploy/detection_tensorrt_dynamic-192x192-960x960.py'
model_cfg = '../mmyolo/configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
device = 'cuda:0'
backend_model = ['./work_dir/end2end.engine']
image = '../mmyolo/demo/demo.jpg'
# read deploy_cfg and model_cfg
deploy_cfg, model_cfg = load_config(deploy_cfg, model_cfg)
# build task and backend model
task_processor = build_task_processor(model_cfg, deploy_cfg, device)
model = task_processor.build_backend_model(backend_model)
# process input image
input_shape = get_input_shape(deploy_cfg)
model_inputs, _ = task_processor.create_input(image, input_shape)
# do model inference
with torch.no_grad():
result = model.test_step(model_inputs)
# visualize results
task_processor.visualize(
image=image,
model=model,
result=result[0],
window_name='visualize',
output_file='work_dir/output_detection.png')
SDK 模型推理¶
ONNXRuntime¶
以上述模型转换后的 end2end.onnx 为例,您可以使用如下代码进行 SDK 推理:
from mmdeploy_runtime import Detector
import cv2
img = cv2.imread('../mmyolo/demo/demo.jpg')
# create a detector
detector = Detector(model_path='work_dir',
device_name='cpu', device_id=0)
# perform inference
bboxes, labels, masks = detector(img)
# visualize inference result
indices = [i for i in range(len(bboxes))]
for index, bbox, label_id in zip(indices, bboxes, labels):
[left, top, right, bottom], score = bbox[0:4].astype(int), bbox[4]
if score < 0.3:
continue
cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0))
cv2.imwrite('work_dir/output_detection.png', img)
TensorRT¶
以上述模型转换后的 end2end.engine 为例,您可以使用如下代码进行 SDK 推理:
from mmdeploy_runtime import Detector
import cv2
img = cv2.imread('../mmyolo/demo/demo.jpg')
# create a detector
detector = Detector(model_path='work_dir',
device_name='cuda', device_id=0)
# perform inference
bboxes, labels, masks = detector(img)
# visualize inference result
indices = [i for i in range(len(bboxes))]
for index, bbox, label_id in zip(indices, bboxes, labels):
[left, top, right, bottom], score = bbox[0:4].astype(int), bbox[4]
if score < 0.3:
continue
cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0))
cv2.imwrite('work_dir/output_detection.png', img)
除了python API,mmdeploy SDK 还提供了诸如 C、C++、C#、Java等多语言接口。 你可以参考样例学习其他语言接口的使用方法。